Step 3: Explore Ways to Work With the Data
Once the data is in the HPE Ezmeral Data Fabric platform, explore the various features and components available on the platform and determine your path. You may want to access data in its initial format or perform some data modeling or processing prior to accessing the data.
The following sections provide some examples to help you determine which approach will work for your particular use case.
Process Data
When developing applications that ingest data, consider if the data requires some processing before the data can be consumed or stored.
- Process the Data Before Querying the Data
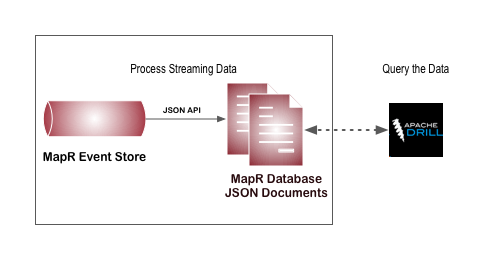
To efficiently query data, you may want to convert the data into a different format. For example, if you want to use Drill to query event data, you can convert streaming data from topics to a JSON table to enable more efficient querying. To do this, ingest event data using HPE Ezmeral Data Fabric Streams, use the HPE Ezmeral Data Fabric Streams API to read the data from topics and the JSON API to store the data in a JSON table, then use Drill to query the JSON tables.
- Process Data before Storing the Data
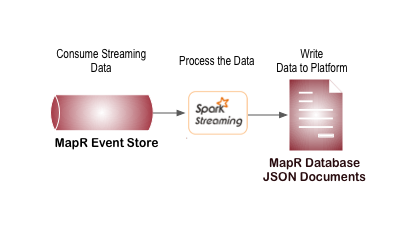
You may also want to process the data based on business needs to perform some pre-processing before long term storage. For example, you can consume streaming data from a HPE Ezmeral Data Fabric Streams topic with a Spark Streaming application which performs calculations or adds additional data before storing the data in a different data-store such as a HPE Ezmeral Data Fabric Database JSON table.
- Perform Calculations as the Data is Stored
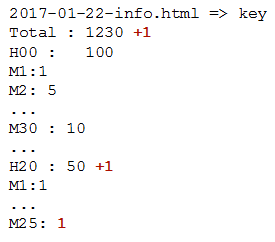
You may want to modify a single row in a table and then incrementally aggregate data. For example, you can use HPE Ezmeral Data Fabric Database tables to store large amounts of customer information or product catalog data and then read and write to a subset of that data. Then, modify a single row in a table to incrementally aggregate data. For example, to aggregate the number of clicks on a page, you can have a row key for each date and page. Internally, you can design the table to increment based on timestamp. The following example shows a row of data for the info page on 2017-02-22:
- Process Large Sets of Data
There are also many methods to process files in their initial state. To process large sets of data on the HPE Ezmeral Data Fabric File Store, it is common to use Spark or MapReduce applications. MapReduce applications perform parallel,distributed processing of data in batches and are therefore a great way to process large datasets. Spark applications can be used to iteratively process large sets of data with machine learning algorithms. For an example of using a machine learning algorithm with a Spark application, see Building a Recommendation Engine with Spark.
Access Data
There are many use cases for why you might want to access data and many methods to access the data. Operational applications or E-commerce services may want to access data on the HPE Ezmeral Data Fabric platform to provide customers a view of transactional data. Business users may want to view user profile data or submit queries through a BI tool to visually analyze the data.
- Access Data in HPE Ezmeral Data Fabric File Store
The most common way to access data in the HPE Ezmeral Data Fabric File Store is via a NFS mount point that is remote or local to the cluster. You can use HDFS commands as well but they are generally only used for migrating hadoop applications to the HPE Ezmeral Data Fabric platform. If you require high throughput, security, and scalability, consider installing the POSIX client as this provides a more efficient way to access data in the HPE Ezmeral Data Fabric File Store. You can also query the data directly using Drill.
- Access Data in HPE Ezmeral Data Fabric Database
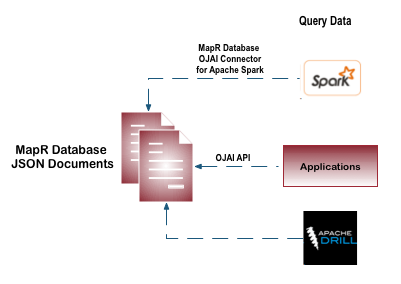
The methods that you can use to access HPE Ezmeral Data Fabric Database table data differs based on the table type. You can access HPE Ezmeral Data Fabric Database binary table data with the HBase shell and applications that use the HBase API. You can access HPE Ezmeral Data Fabric Database JSON table data with the dbshell, and java applications that use the OJAI API. You can also use Drill or Spark to query HPE Ezmeral Data Fabric Database binary and JSON table data directly.
- Access Data in HPE Ezmeral Data Fabric Streams
Data in HPE Ezmeral Data Fabric Streams can be accessed by one or more stream consumers and the number of consumers can change over time depending on business needs.
Similar to the various ways you can write data to topics a stream, data in stream topics can be accessed by applications that utilize the Kafka API or a REST interface. You can also use Spark to query streams for new messages at a given interval and access any new messages that are available.
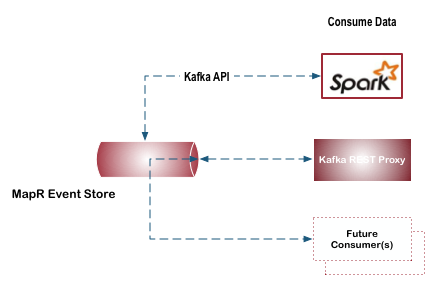
HPE Ezmeral Data Fabric Streams provides flexibility to add new consumers without making changes to the producer application. For example, you have a HPE Ezmeral Data Fabric Streams producer that writes all twitter feeds to a stream. Today, this stream is accessed by a single consumer application that provides access to twitter feeds with content related to IOT. The next week, there may be a request check for how many tweets originate from a specific account. Providing access to different data in an existing stream can be achieved by creating a new consumer which reads from the same stream.