Primary-Secondary Replication
In this topology, you replicate one way from source tables to replicas. The replicas can be in a remote cluster or in the cluster where the source tables are located.
Several topologies are possible for primary-secondary replication:
Replication from one source table to one or more replica tables
In this topology, updates on a source table are replicated to one or more replicas, but updates to the replicas are not replicated back to the source table.
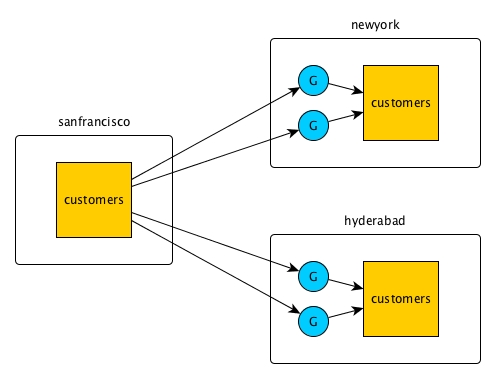
For example, in this diagram, updates to the customers table in the
cluster sanfrancisco are being replicated to the newyork
and hyderabad clusters. The circles marked G each represent a
HPE Ezmeral Data Fabric gateway.
However, changes to the table in the newyork and
hyderabad clusters are not replicated back to the table in the
sanfrancisco cluster.
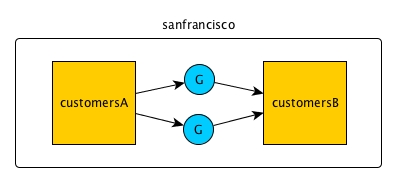
You can also replicate within a single cluster. In this example, the cluster
sanfrancisco contains both the source table and the replica.
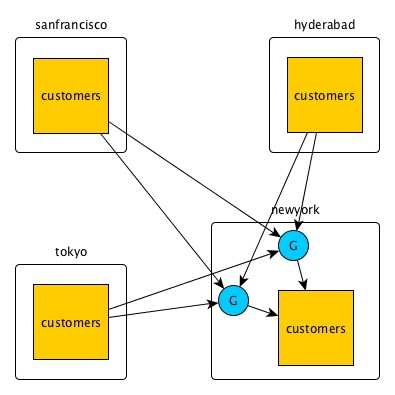
Many-to-one replication
Multiple source tables can replicate to a single replica. In this diagram, operations on
customers tables in three different clusters are replicated via
gateways to the customers table in the newyork
cluster.
One-to-many replication
A single source table can replicate to multiple replicas. In this diagram, operations on
the customers table in the sanfrancisco cluster are
replicated via gateways to replicas in three other clusters.
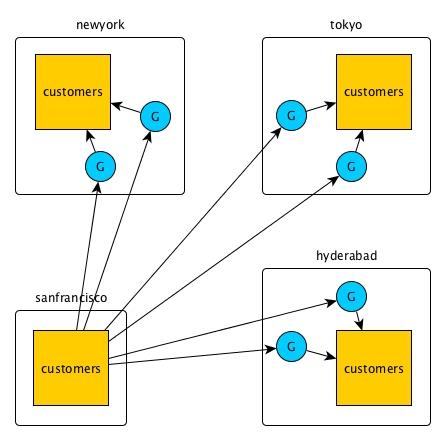
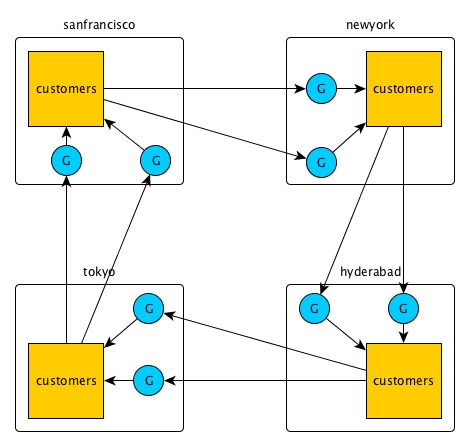
Replication loops
When three or more tables need to be kept in sync, you can set up primary-secondary replication between pairs of them to form a replication loop. Operations on a table are propagated to the other clusters in the loop, but there is no attempt to reapply the operations at the originating table. This is because the operations are tagged with a universally unique identifier (UUID) that identifies the table where the operations originated.
In this diagram, for example, operations on the customers table in the
hyderabad cluster are replicated first to the
customers table in the tokyo cluster. The operations
are then replicated from the tokyo cluster to the
customers table in the sanfrancisco cluster. Finally,
the operations are replicated from the sanfrancisco cluster to the
customers table in the newyork cluster. The
newyork cluster does not replicate the operations to the
customers table in the hyderabad cluster.
Primary-Secondary replication in two directions
You can combine primary-secondary replication configurations to replicate data between clusters. Two clusters engaged in replication can each act as a source cluster and a destination cluster.
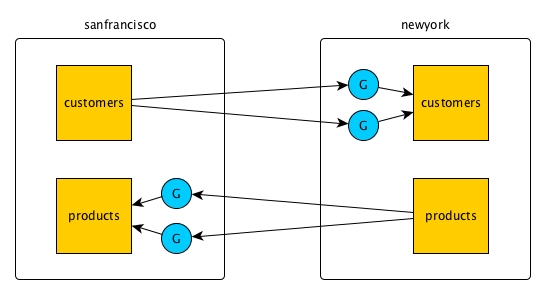
In this example, the data in the customers table in the cluster
sanfrancisco is replicated to the customers table in
the cluster newyork. At the same time, the data in the
products table in the newyork cluster is replicated to
the products table in the cluster sanfrancisco.
In all primary-secondary configurations, changes made to replica tables are not replicated back to source tables. Therefore, if the replicated data is modified at the replica by client applications, the replica will become out of sync with the source table.
For example, you might replicate the two column families personal and
purchases from the customer table in the
sanfrancisco cluster to the customers table in the
newyork cluster, as in this diagram. (For simplicity, the blue circle
labeled G represents two or more gateways, rather than one as in the other diagrams in this
topic.)
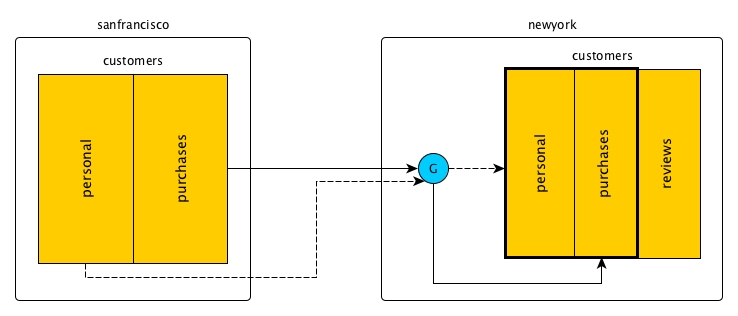
In primary-secondary replication, no updates to a replica are replicated back to the
source. Any updates that applications might make to those two column families in the
customers table in the newyork cluster will not be
replicated to the customers table in the sanfrancisco
cluster.
However, you do not have to protect a replica from all updates that are not due to
replication. For example, the customers table in the
newyork cluster might have an additional column family that is not
populated with replicated data: reviews.