Table Rowkey Design
The design of a table's rowkeys affects the speed at which client applications can access data and the database performance if hotspotting occurs. The better the design, the faster the data access.
What is a Row Key?
- For binary tables:
- A row key identifies a row in a HPE Ezmeral Data Fabric Database binary table.
- For JSON tables:
- A row key identifies a row in a HPE Ezmeral Data Fabric Database JSON table. You specify row keys in the _id field in JSON documents.
For example, if the value of the _id field in a JSON document is user000001, that value is also the rowkey for the row in which the JSON document is stored in a JSON table.
Avoiding Hotspotting
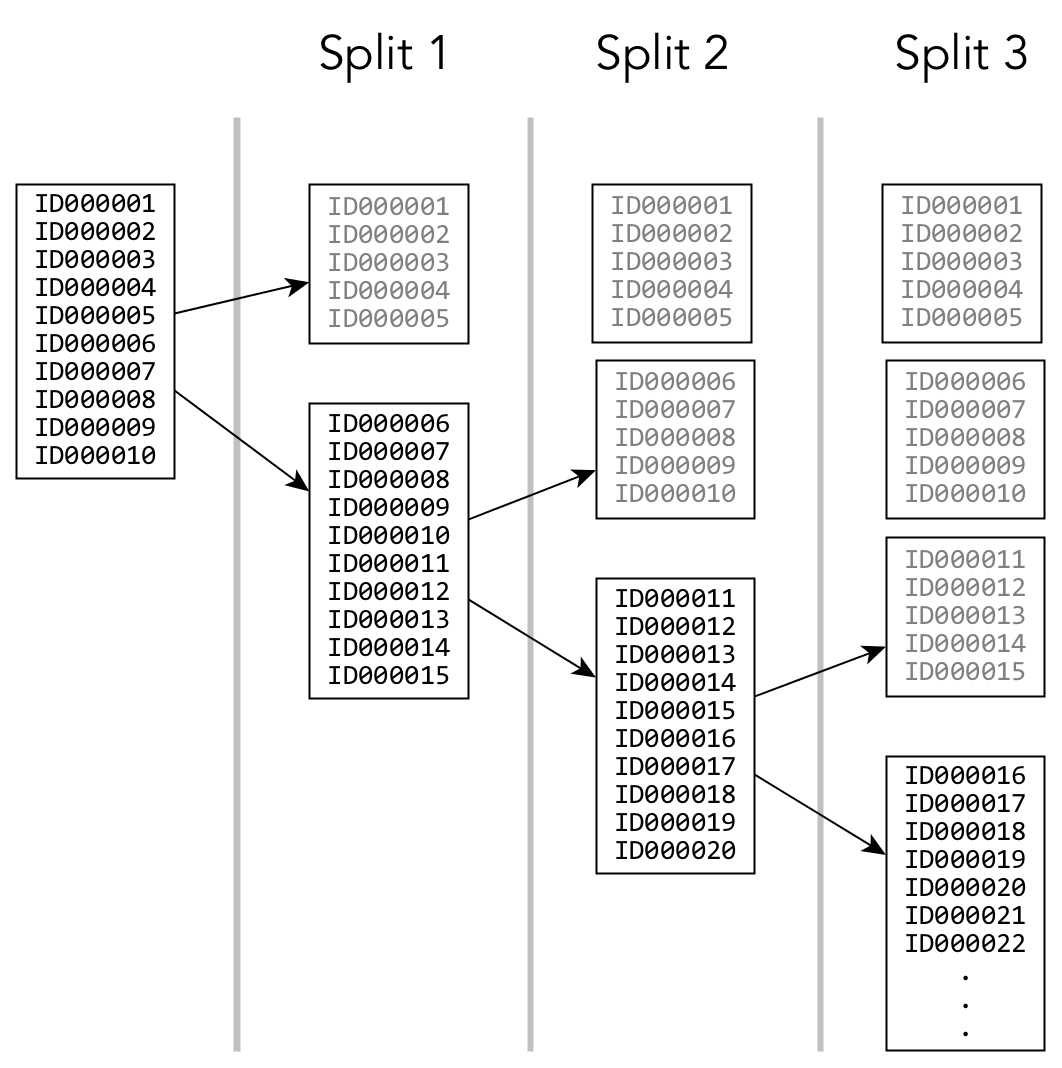
With HPE Ezmeral Data Fabric Database tables, the cluster handles sequential keys and table splits to keep potential hotspots moving across nodes, decreasing the intensity and performance impact of hot spots. However, hotspotting can still hamper database performance.
There are two strategies that you can use to avoid hotspotting:
- Hashing keys
- To spread write and insert activity across the cluster, you can randomize sequentially generated keys by hashing the keys, inverting the byte order. Note that these strategies come with trade-offs. Hashing keys, for example, makes table scans for key subranges inefficient, since the subrange is spread across the cluster.
- Salting keys
- Instead of hashing the key, you can salt the key by prepending a few bytes of
the hash of the key to the actual key. For a key based on a timestamp, for
instance, a timestamp value of
1364248490has an MD5 hash that ends withffe5. By making the key for that rowffe51364248490, you avoid hotspotting. Because you know that the first four digits are a hash salt, you can derive the original timestamp by dropping those digits.
Composite Keys
Each row in a table can have only a single key. You can create composite keys to approximate multiple keys in a table. A composite key contains several individual IDs joined together, for example userID and applicationID. You can then scan for the specific segments of the composite row key that represent the original, individual ID.
Because rows are stored in sorted order, you can affect the results of the sort by changing the ordering of the fields that make up the composite row key. For example, if your application IDs are generated sequentially but your user IDs are not, using a composite key of userID+applicationID will store all rows with the same user ID closely together. If you know the userID for which you want to retrieve rows, you can specify the first userID row and the first userID+1 row as the start and stop rows for your scan, then retrieve the rows you're interested in without scanning the entire table.
When designing a composite key, consider how the data will be queried during production use. Place the fields that will be queried the most often towards the front of the composite key, bearing in mind that sequential keys will generate hotspotting.
- For binary tables:
-
You must create your own custom logic for working with composite keys in applications that use the HBase Java API. This API does not have built-in support for composite keys.
- For JSON tables:
-
You must create your own custom logic for working with composite keys in applications that use the HPE Ezmeral Data Fabric Database OJAI Java API library. This API library does not have built-in support for composite keys.