Mirroring Topics with HPE Data Fabric MirrorMaker 2
MirrorMaker 2.0 is a multi-cluster, cross-data-center replication engine based on the Kafka Connect framework. MirrorMaker 2 is available starting in EEP 8.0.0.
- from Apache Kafka clusters to Apache Kafka clusters.
- from Apache Kafka clusters to streams in HPE Data Fabric clusters.
- from streams in HPE Data Fabric clusters to Apache Kafka clusters.
- between streams in HPE Data Fabric clusters.
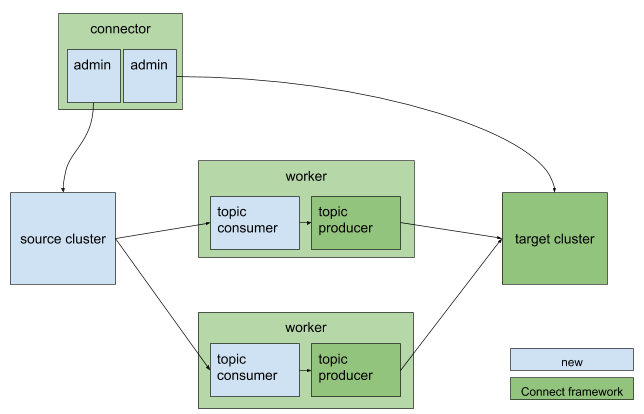
MirrorMaker 2 Architecture
MirrorMaker 2 uses the Kafka Connect framework to simplify configuration and scaling. Both source and sink connectors are provided to enable complex flows between multiple Kafka clusters and across data centers via existing Kafka Connect clusters. The main MirrorMaker 2 components are actually Kafka connectors, as described in the following list:
- The MirrorSourceConnector replicates records from local to remote clusters and enables offset synchronization.
- The MirrorCheckpointConnector manages consumer offset synchronization, emits checkpoints, and enables failover.
- The MirrorHeartbeatConnector provides heartbeats, monitoring of replication flows, and client discovery of replication topologies, which can be more complex than for the original MirrorMaker.
As shown in the following MirrorMaker 2 architecture diagram, the source and sink connectors contain a pair of producers and consumers to replicate records, and a pair of AdminClients to propagate configuration changes:
Prerequisites
When using HPE Data Fabric streams as the source or target:
- Ensure that the destination stream in the HPE Data Fabric cluster exists. To create a stream, run the
maprcli stream createcommand. - Ensure that the ID of the user that runs MirrorMaker 2 has the
producepermandtopicpermpermissions on the stream.
When using an Apache Kafka cluster as the source or target:
- Verify that a connection to the Apache Kafka cluster exists.
Connector Configuration Properties for MirrorMaker 2
Use the .stream property instead of the
.bootstrap.servers property when an HPE Data Fabric stream is the source
or the target.
| Property | Default | Description |
|---|---|---|
| name | required | name of the connector, e.g. "us-west->us-east" |
| topics | empty string | regex of topics to replicate, e.g. "topic1|topic2|topic3". Comma-separated lists are also supported. |
| topics.blacklist | ".*\.internal, .*\.replica, __consumer_offsets" or similar | topics to exclude from replication |
| groups | empty string | regex of groups to replicate, e.g. ".*" |
| groups.blacklist | empty string | groups to exclude from replication |
| source.cluster.alias | required | name of the cluster being replicated |
| target.cluster.alias | required | name of the downstream Kafka cluster |
| source.cluster.stream | required or can be replaced by bootstrap.servers | stream from upstream HPE Data Fabric cluster to replicate |
| target.cluster.stream | required or can be replaced by bootstrap.servers | Stream from downstream HPE Data Fabric cluster |
| source.cluster.bootstrap.servers | required or can be replaced by stream | upstream cluster to replicate |
| target.cluster.bootstrap.servers | required or can be replaced by stream | downstream cluster |
| sync.topic.configs.enabled | true | whether or not to monitor source cluster for configuration changes |
| sync.topic.acls.enabled | true | whether to monitor source cluster ACLs for changes |
| emit.heartbeats.enabled | true | connector should periodically emit heartbeats |
| emit.heartbeats.interval.seconds | 5 (seconds) | frequency of heartbeats |
| emit.checkpoints.enabled | true | connector should periodically emit consumer offset information |
| emit.checkpoints.interval.seconds | 5 (seconds) | frequency of checkpoints |
| refresh.topics.enabled | true | connector should periodically check for new topics |
| refresh.topics.interval.seconds | 5 (seconds) | frequency to check source cluster for new topics |
| refresh.groups.enabled | true | connector should periodically check for new consumer groups |
| refresh.groups.interval.seconds | 5 (seconds) | frequency to check source cluster for new consumer groups |
| readahead.queue.capacity | 500 (records) | number of records to let consumer get ahead of producer |
| replication.policy.class | org.apache.kafka.connect.mirror.DefaultReplicationPolicy | use LegacyReplicationPolicy to mimic legacy MirrorMaker |
| heartbeats.topic.retention.ms | 1 day | used when creating heartbeat topics for the first time |
| checkpoints.topic.retention.ms | 1 day | used when creating checkpoint topics for the first time |
| offset.syncs.topic.retention.ms | max long | used when creating offset sync topic for the first time |
| replication.factor | 2 | used when creating remote topics |
| Property | Description |
|---|---|
| source.cluster.consumer.* | overrides for the source-cluster consumer |
| source.cluster.producer.* | overrides for the source-cluster producer |
| source.cluster.admin.* | overrides for the source-cluster admin |
| target.cluster.consumer.* | overrides for the target-cluster consumer |
| target.cluster.producer.* | overrides for the target-cluster producer |
| target.cluster.admin.* | overrides for the target-cluster admin |
Example Configuration File
mm2.properties configuration file example shows the
configuration for an HPE Data Fabric stream to Apache Kafka cluster
workflow.# Datacenters.
clusters = source, target
source.stream = /str
target.bootstrap.servers = 192.168.33.12:9092
# Source and target cluster configurations.
source.config.storage.replication.factor = 1
target.config.storage.replication.factor = 1
source.offset.storage.replication.factor = 1
target.offset.storage.replication.factor = 1
source.status.storage.replication.factor = 1
target.status.storage.replication.factor = 1
source->target.enabled = true
target->source.enabled = false
# Mirror maker configurations.
offset-syncs.topic.replication.factor = 1
heartbeats.topic.replication.factor = 1
checkpoints.topic.replication.factor = 1
topics = .*
groups = .*
tasks.max = 1
replication.factor = 1
refresh.topics.enabled = true
sync.topic.configs.enabled = true
refresh.topics.interval.seconds = 30
topics.blacklist = .*[\-\.]internal, .*\.replica, __consumer_offsets
groups.blacklist = console-consumer-.*, connect-.*, __.*
# Enable heartbeats and checkpoints.
source->target.emit.heartbeats.enabled = true
source->target.emit.checkpoints.enabled = trueCommand Syntax
/opt/mapr/kafka/kafka-<version>/bin/connect-mirror-maker.sh mm2.propertiesLogs are written to the console instead of log files. You can change where logs are written
by editing the
/opt/mapr/kafka/kafka-<version>/config/connect-mirror-maker-log4j.properties
file.
Limitations
There are several limitations that differentiate HPE Data Fabric MirrorMaker 2 from Apache Kafka MirrorMaker 2:
- MirrorCheckpointConnector is not supported by HPE Data Fabric MirrorMaker 2; therefore, mirroring is based only on MirrorSourceConnector and MirrorHeartbeatConnector.
- Access Control Lists (ACLs) synchronization is not supported because HPE Data Fabric Streams are not supported ACL.
- Broker configurations that include any of the
log.properties are not synchronized. For example, if the broker configuration contains thelog.dirproperty, the broker configuration is not synchronized across all brokers in the cluster.