Loading Documents into JSON Tables
There are three command-line utilities for loading documents into JSON tables: mapr copytable, mapr importtable (which works in
conjunction with the mapr exporttable utility), and mapr importJSON
You can choose whether to have these utilities perform bulk loads or incremental loads.
For bulk loads, the -bulkload parameter of the JSON table must be set to
true. During a bulk load, client applications are unable to access the
table. After the utility is finished, you must set the table's -bulkload
parameter to false, so that client applications can access the table again.
When you set the -bulkload parameter to true, you cannot enable
replication on the table. Since this effectively disables logging on the table, HPE Ezmeral Data Fabric Database
also does not capture log data that Elasticsearch can use to index the table.
mapr copytable
The mapr copytable utility copies documents --
all documents or a subset determined by a range of row keys, and all fields or a subset of
fields -- directly from oneJSON table to another.
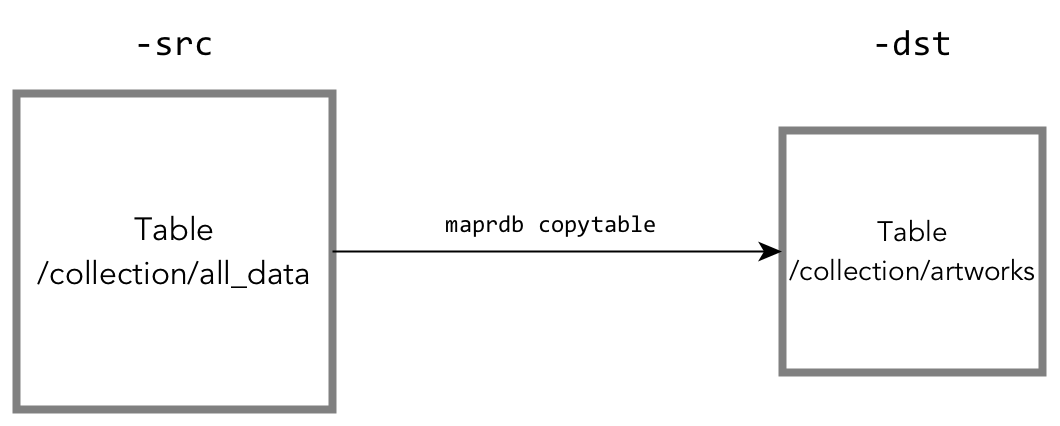
For reference information about this utility, see mapr copytable.
mapr exporttable and
mapr importtable
The mapr exporttable utility exports data from a JSON table to binary
sequence files that you can import into another JSON table by using the
mapr importtable utility.
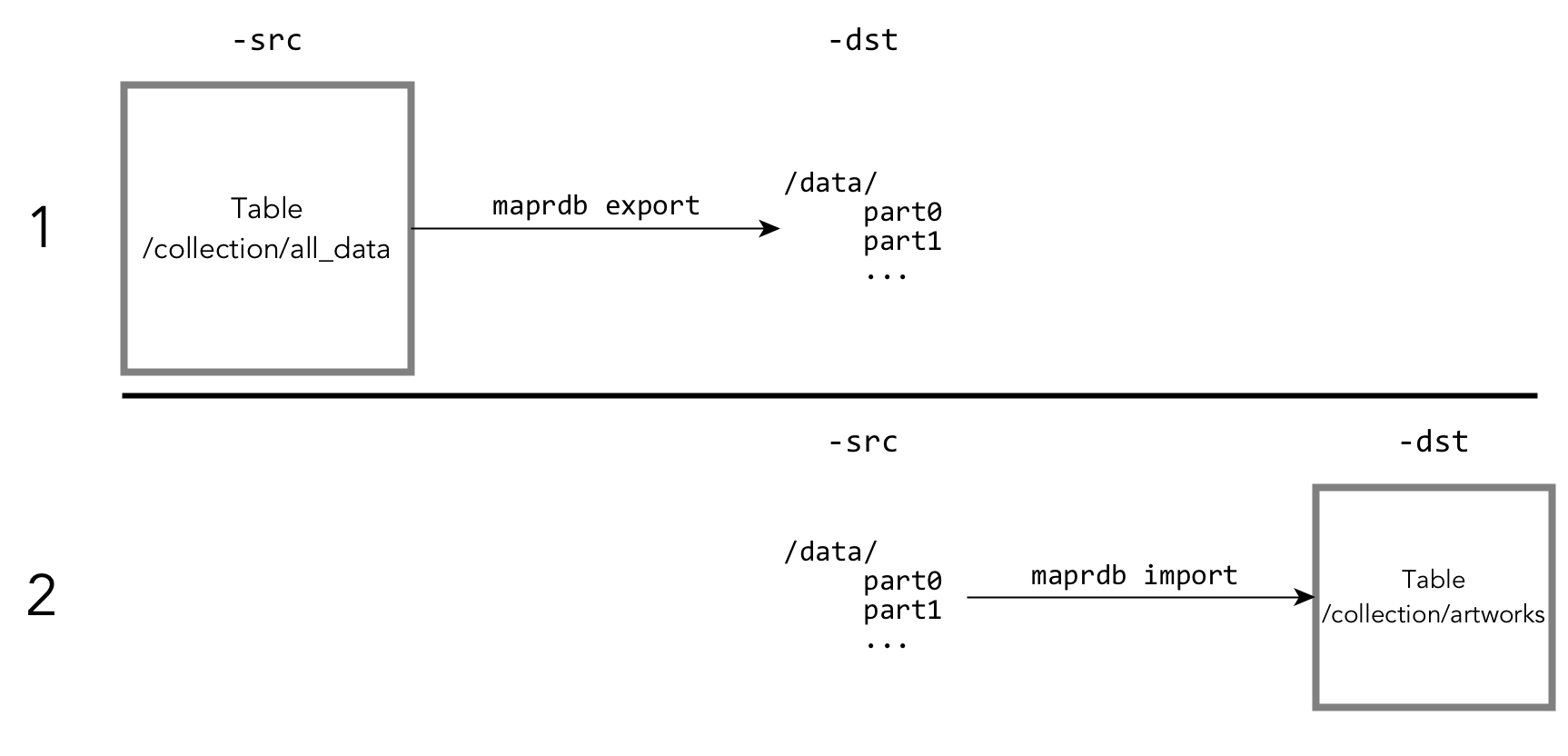
The destination directory is created by the mapr exporttable utility. To prevent accidental
overwriting of data, the mapr exporttable
utility fails if the destination directory already exists.
The command for running
the mapr importtable utility in step 2 of the
diagram above would look like this:
mapr importtable -src /data/* -dst /collection/artworks
The
-columns parameter of the mapr exporttable utility lets you export subsets of
the fields in the documents that are in a table. For example, to export field
b, the fields under it, and field d from documents with
the following structure, the command to run the mapr exporttable utility would look like this:
mapr exporttable -columns a.b,c.d -src /collection/all_data -dst /data

For reference information about these commands, see HPE Ezmeral Data Fabric Database JSON ExportTable and ImportTable.
mapr importJSON
This utility imports one or more JSON documents that are text files into a JSON table.
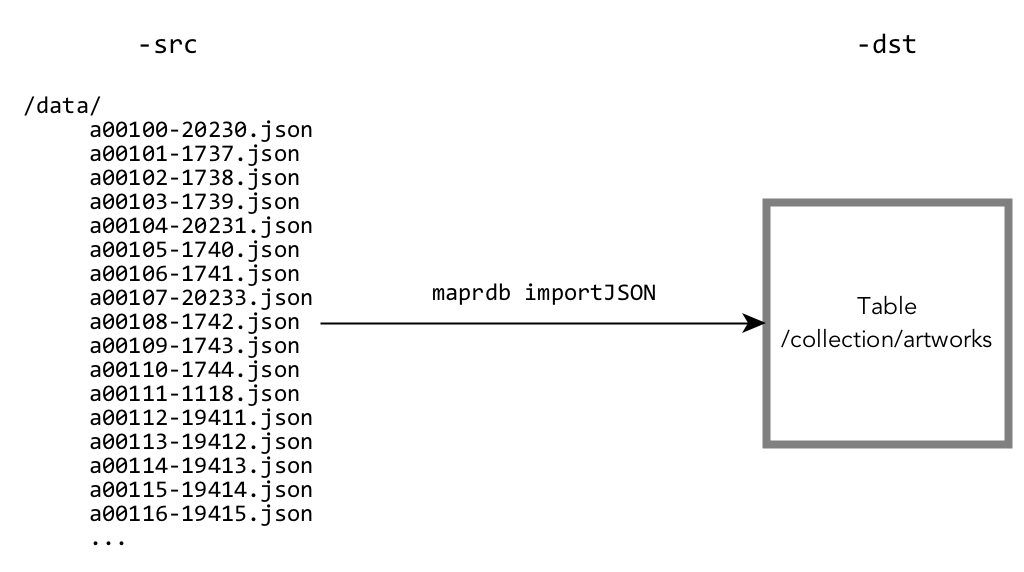
If the each document does not already contain an _id field to use as a
document ID, the mapr importJSON utility
adds an _id field during the import. Use the -idfield
parameter to specify the name of the field that contains the value to copy into the value of
the _id field.
For example, each document might have a product_ID field that contains a
universally unique identifier. You could run the utility with this command:
mapr importJSON -idfield "product_ID" -src /data/* -dst /collection/artworksFor reference information about this command, see the mapr importJSON
command.