Example Cluster Designs
Describes how to design a Data Fabric cluster for maximum availability, fault-tolerance, and performance.
Design Priorities
- Performance
- Fault-tolerance
- Cost
- Ease of use
- Supportability
- Reliability
Priority 1 - Maximize Fault Tolerance
- Ensure an odd number of ZooKeeper services. ZooKeeper fault tolerance depends on a quorum of ZooKeeper services being available. At least three ZooKeeper services are recommended. For a higher level of fault tolerance, use five ZooKeeper services. With five ZooKeepers, the quorum is maintained even if two services are lost.
- For other services, it makes sense for them to be at least as reliable as ZooKeeper. Generally, this means at least two instances of the service for three ZooKeepers and three instances for five ZooKeepers.
- Include enough CLDBs to be as reliable as ZooKeeper. Because CLDBs use a primary-secondary configuration, a Data Fabric cluster can function with an odd or even number of
CLDBs. The recommended minimum number of active CLDBs is two. To tolerate failures, more
CLDBs are needed:
- If you have three ZooKeepers, configure at least three CLDBs.
- If you have five ZooKeepers, configure at least four CLDBs. With four CLDBs, the cluster can tolerate two CLDB failures and still provide optimal performance. Adding a fifth CLDB does not increase failure tolerance in this configuration.
- Include enough Resource Manager processes to be as reliable as ZooKeeper. Only one
Resource Manager is active at a time:
- If you have three ZooKeepers, you need at least two Resource Managers.
- If you have five ZooKeepers, you need at least three Resource Managers. Three Resource Managers can survive the loss of two ZooKeepers.
- For most Data Fabric clusters, the recommended
configuration is:
- Three (3) ZooKeepers
- Three (3) CLDBs
- Two or three (2-3) Resource Managers
| ZooKeepers | CLDBs | Resource Managers | ZK/CLDB/RM Failures Tolerated |
|---|---|---|---|
| 3 | 21 | 2 | 1 |
| 3 | 3 | 2 | 1 |
| 5 | 4 | 3 | 2 |
| 5 | 52 | 3 | 2 |
1 For optimal failure handling, the minimum number of CLDBs is three; hence, three or more CLDBs are recommended. With two CLDBs, the failure of one does not result in an outage, but recovery can take longer than with three CLDBs.
2 Using five CLDBs does not improve fault-tolerance significantly when compared with four CLDBs. However, it can be convenient to have the same number of CLDBs as ZooKeepers.
Priority 2 - Minimize Resource Contention
Every service on a node represents a tax on the resources provided by that node. Spreading services evenly across nodes maximizes performance and helps to keep failures isolated to failure domains. Because of power and networking considerations, a rack is usually the most common failure domain.
- Spread like services across racks as much as possible. While not necessary, it is also convenient to put them in the same position, if possible.
- To maximize availability, use three or more racks even for small clusters. Using two
racks is not recommended. If a cluster has three ZooKeepers, using two racks means one
of the racks will host two ZooKeepers. In this scenario, a loss of a rack having two
ZooKeepers can jeopardize the cluster.
- For services that are replicated, make sure the replicas are in different racks.
- Put the Resource Manager and CLDB services on separate nodes, if possible.
- Put the ZooKeeper and CLDB services on separate nodes, if possible.
- Some administrators find it convenient to put web-oriented services together on nodes with lower IP addresses in a rack. This is not required.
- Avoid putting multiple resource-heavy services on the same node.
- Spread the following resources across all data nodes:
- Clients
- Drill
- NFS
Priority 3 - Promote High Availability
- Kafka REST
- HBase Thrift
- HBase REST
- HTTPFS
- HiveServer 2 (HS2)
- Hue
- Kafka Connect
- Data Fabric Data Access Gateway
- Data Fabric Gateway
- Keycloak
- OpenTSDB
- WebHCat
- WebServer
Priority 4 - Use Dedicated Nodes for Key Services on Large Clusters (50-100 Nodes)
- Use dedicated nodes for CLDB, ZooKeeper, and Resource Manager.NOTEDedicated nodes have the benefit of supporting fast fail-over for file-server operations.
- If fast fail-over is not critical and you need to minimize hardware costs, you may combine the CLDB and ZooKeeper nodes. For example, a large cluster might include 3 to 9 such combined nodes.
- If necessary, review and adjust the hardware composition of CLDB, ZooKeeper, and Resource Manager nodes. Once you have chosen to use dedicated nodes for these services, you might determine that they do not need to be identical to other cluster nodes. For example, dedicated CLDB and ZooKeeper nodes probably do not need as much storage as other cluster nodes.
- Avoid configuring Drill on CLDB or ZooKeeper nodes.
Example Clusters
Example 1: 6-Node Cluster (Single Rack)
Example 1 shows a 6-node cluster contained in a single rack. When only a single rack is available, this example can work for small clusters. However, the recommended best practice for all clusters, regardless of size, is to use three or more racks, if possible.
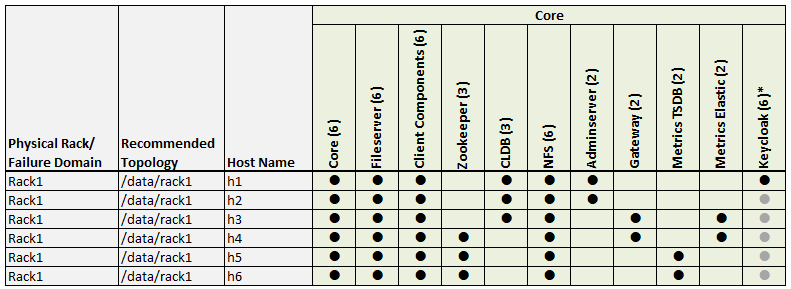
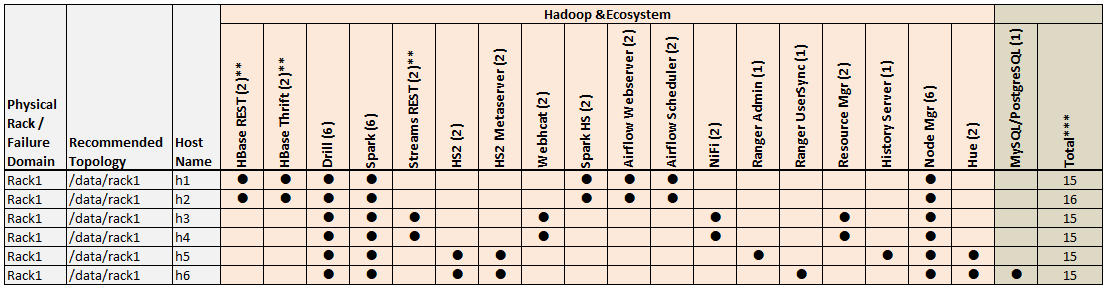
Example 1 Footnotes
* The Keycloak binary is installed on all nodes, but the service is started on only one node.
** Denotes a service that is lightweight and stateless. For greater performance, consider running these services on all nodes and adding a load balancer to distribute network traffic.
*** The Total column shows the total number of Core, Hadoop, and Ecosystem components installed on each host node for the example cluster.
Example 2: 12-Node Cluster (3 Racks)
Example 2 shows a 12-node cluster contained in three racks:
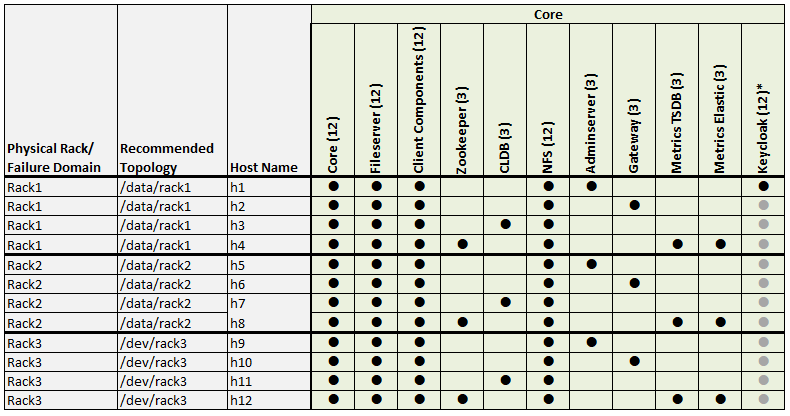
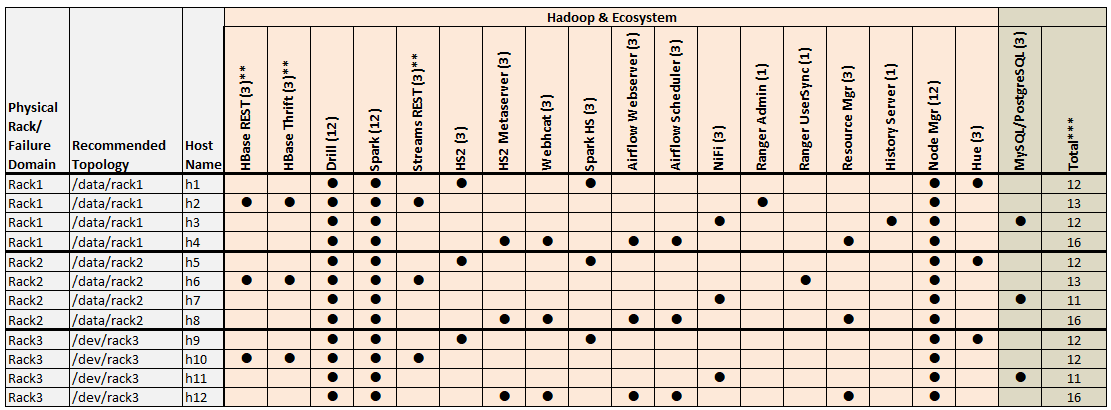
Example 2 Footnotes
* The Keycloak binary is installed on all nodes, but the service is started on only one node.
** Denotes a service that is lightweight and stateless. For greater performance, consider running these services on all nodes and adding a load balancer to distribute network traffic.
*** The Total column shows the total number of Core, Hadoop, and Ecosystem components installed on each host node for the example cluster.
Example 3: 50-Node Cluster (5 Racks)
Examples 3 shows a 50-node cluster contained in five racks:
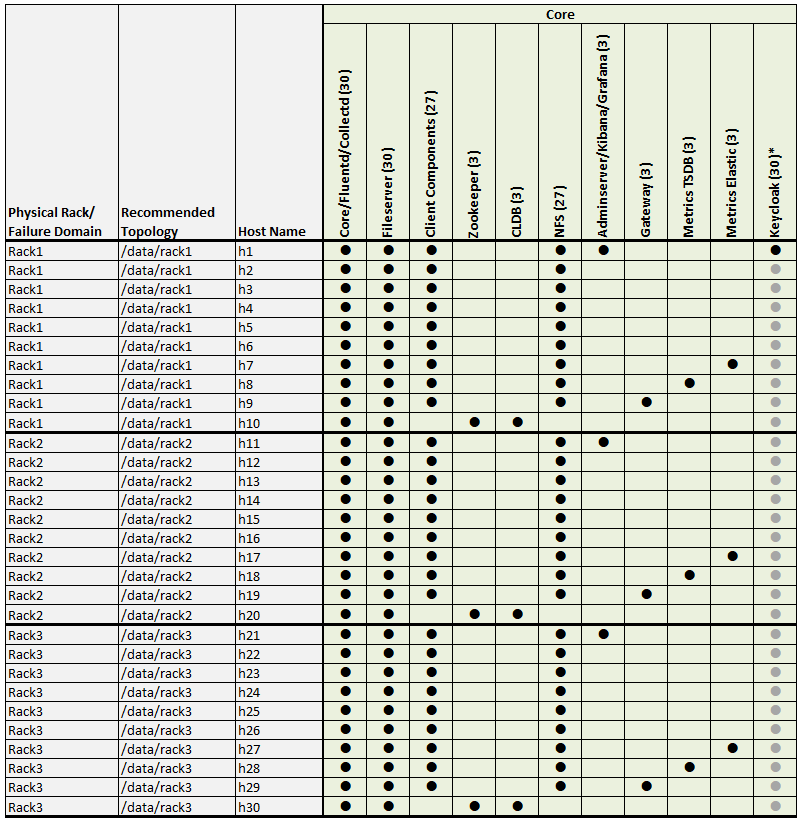
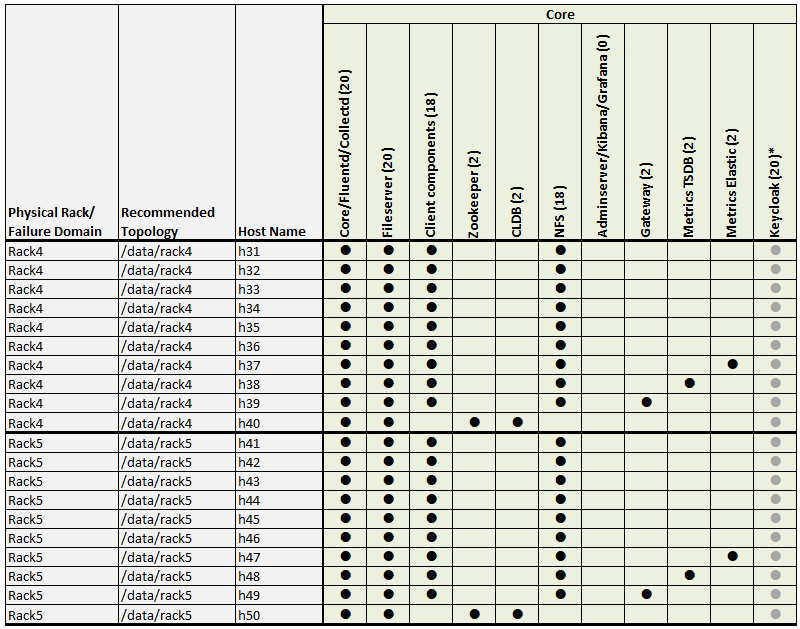
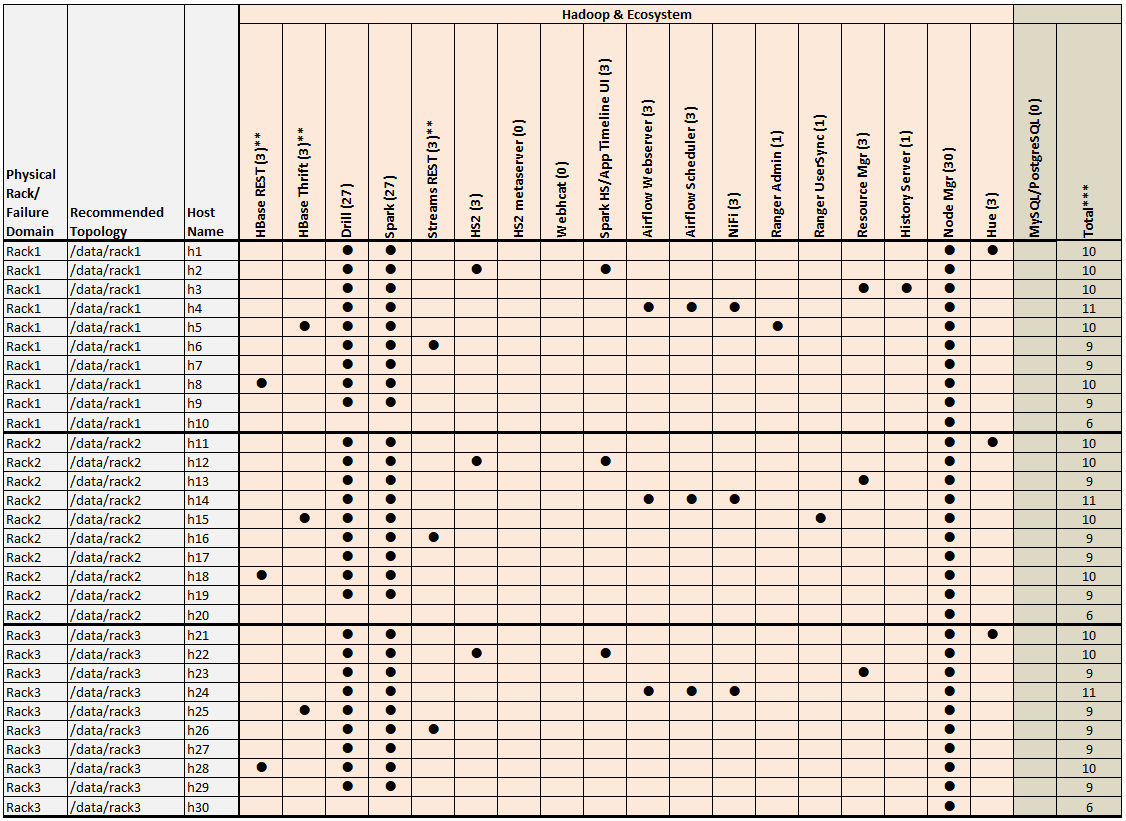
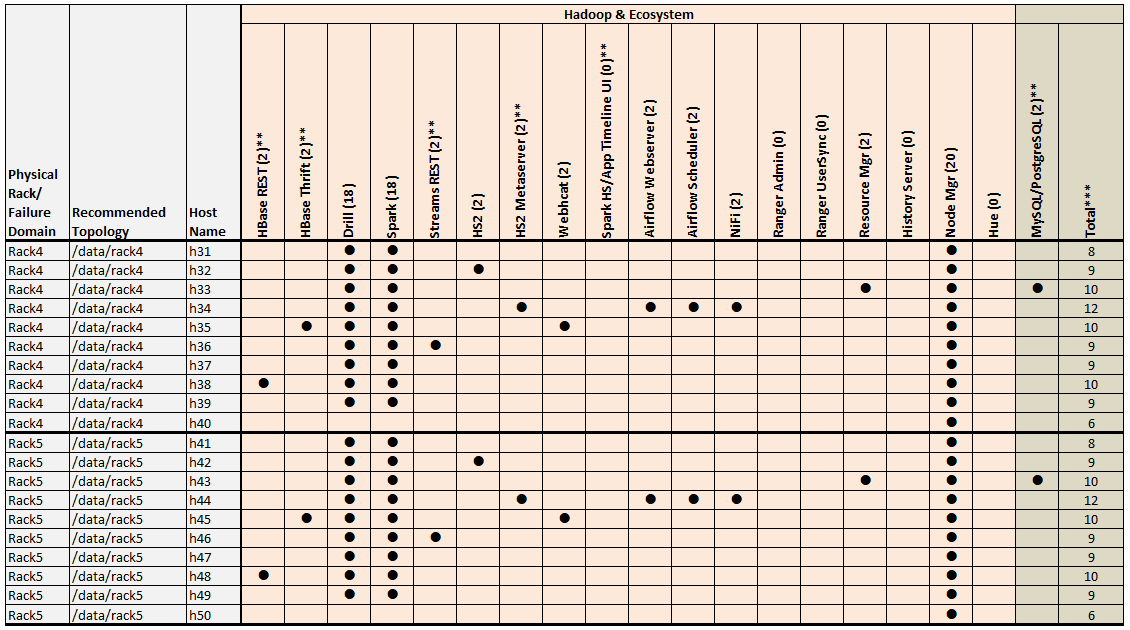
Example 3 Footnotes
* The Keycloak binary is installed on all nodes, but the service is started on only one node.
** Denotes a service that is lightweight and stateless. For greater performance, consider running these services on all nodes and adding a load balancer to distribute network traffic.
*** The Total column shows the total number of Core, Hadoop, and Ecosystem components installed on each host node for the example cluster.