ZooKeeper
Provides an overview of the ZooKeeper service.
ZooKeeper is a coordination service for distributed applications. It provides a shared
hierarchical namespace that is organized like a standard filesystem. The namespace consists
of data registers called znodes, for ZooKeeper data nodes, which are similar to files and
directories. A name in the namespace is a sequence of path elements where each element is
separated by a / character, such as the path /app1/p_2 shown here:
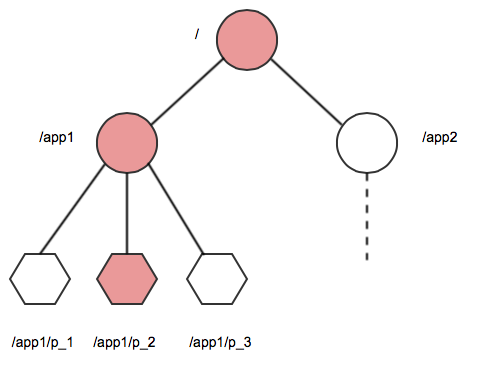
Namespace
The znode hierarchy is kept in-memory within each ZooKeeper server in order to minimize latency and to provide high throughput of workloads.
The ZooKeeper Ensemble
The ZooKeeper service is replicated across a set of hosts called an ensemble. One of the hosts is designated as the leader, while the other hosts are followers. ZooKeeper uses a leader election process to determine which ZooKeeper server acts as the leader, or master. If the ZooKeeper leader fails, a new leader is automatically chosen to take its place.
Establishing a ZooKeeper Quorum
As long as a majority (a quorum) of the ZooKeeper servers are available, the Zookeeper service is available. For example, if the ZooKeeper service is configured to run on five nodes, three of them form a quorum. If two nodes fail (or one is taken off-line for maintenance and another one fails), a quorum can still be maintained by the remaining three nodes. An ensemble of five ZooKeeper nodes can tolerate two failures. An ensemble of three ZooKeeper nodes can tolerate only one failure. As a quorum requires a majority, an ensemble of four ZooKeeper nodes can only tolerate one failure, and therefore offers no advantages over an ensemble of three ZooKeeper nodes. In most cases, you should run three or five ZooKeeper nodes on a cluster. Larger quorum sizes result in slower write operations.
Ensuring Node State Consistency
Each ZooKeeper server maintains a record of all znode write requests in a transaction log on the disk. The ZooKeeper leader issues timestamps to order the write requests, which when executed, updates elements in the shared data store. Each ZooKeeper server must sync transactions to disk and wait for a majority of ZooKeeper servers (a quorum) to acknowledge an update. Once an update is held by a quorum of nodes, a successful response can be returned to clients. By ordering the write requests with timestamps and waiting for a quorum to be established to validate updates, ZooKeeper avoids race conditions and ensures that the node state is consistent.