Implementation of Secondary Indexes
This topic describes how HPE Ezmeral Data Fabric Database implements secondary indexes. It provides an overview of basic architectural concepts and the rationale behind design choices.
Global Indexes
HPE Ezmeral Data Fabric Database implements secondary indexes as global indexes rather than local indexes. With local indexes, each JSON table's regions (also called tablets) has a corresponding index tablet. The JSON table's and index's tablets are co-located. In contrast, with a global index, the index is a single, separate table with its own tablets and split points. Unlike JSON tables, indexes are always auto-split. There is no option to disable auto-splitting. When splitting index tablets, indexes are range partitioned by default. An alternative to range partitioning is to use hash partitioning to avoid creating hot spots.
Global indexes have the following advantages:
- They provide an ordering across all values in the indexed fields. A scan through the index can generate the sort required by ORDER BY clauses.
- They avoid having to read all partitions. When the data is range partitioned, HPE Ezmeral Data Fabric Database can direct index scans to the subset of partitions that qualify the desired key range.
- They require less data processing by minimizing the partitions that need to be read.
In summary, global indexes are well suited for scalable, read intensive use cases.
While global indexes are optimized for read intensive use cases, maintaining a global index incurs more overhead. Updates are more expensive if the JSON table and its indexes are on different nodes in the cluster.
Index Placement
Each secondary index shares the same volume and topology as its JSON table. Users cannot specify the path of an index. This simplifies the behavior of snapshot and mirroring.
Data Flow
After a secondary index has been created on a JSON table, the following occurs when an update (put operation) is made to the table:
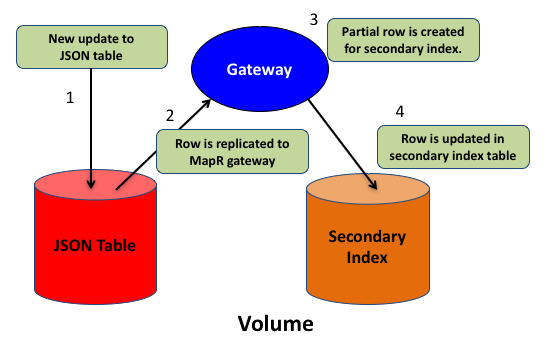
- A document in the JSON table is updated.
- The row with the change is replicated to an internal Data Fabric gateway.
- The Data Fabric gateway determines whether a secondary index is impacted and, if so, creates a partial row that contains the secondary index's indexed and included fields.
- The secondary index row is updated.
When a secondary index is added, data that is already present in the JSON table is propagated to the index using a scan of the JSON table that retrieves indexed and included fields. This replaces step 2. Steps 3 and 4 are executed to populate the index.