Apache Spark
Apache Spark is an open-source processing engine that you can use to process Hadoop data. The following diagram shows the components involved in running Spark jobs. See Spark Cluster Mode Overview for additional component details.
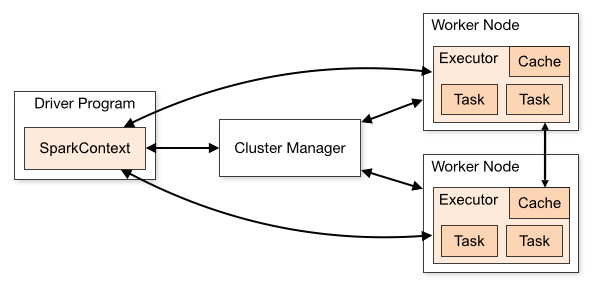
HPE Ezmeral Data Fabric supports the following types of cluster managers:
- Spark's standalone cluster manager
- YARN
This section provides documentation about configuring and using Spark with HPE Ezmeral Data Fabric, but it does not duplicate the Apache Spark documentation.
You can also refer to additional documentation available on the Apache Spark Product Page.