Getting Started with Spark Interactive Shell
After you have a basic understanding of Apache Spark and have it installed and running on your cluster, you can use it to load datasets, apply schemas, and query data from the Spark interactive shell.
Reading Data from file system
- Copy sample data into file system:
- For this example, the dataset constitutes a CSV file of a list of auctions.
- Download the file from GitHub: https://github.com/mapr-demos/getting-started-spark-on-mapr/tree/master/data.
- Copy the file into your cluster, in the/apps/directory, using thecp/scporhadoop putcommand:scp ./data/auctiondata.csv mapr@[mapr-cluster-node]:/mapr/[cluster-name]/apps/ or $ hadoop fs -put ./data/auctiondata.csv /apps- This dataset is from eBay online auctions. The dataset contains the following fields:auctionid - Unique identifier of an auction. bid - Proxy bid placed by a bidder. bidtime - Time (in days) that the bid was placed from the start of the auction. bidder - eBay username of the bidder. bidderrate - eBay feedback rating of the bidder. openbid - Opening bid set by the seller. price - Closing price that the item sold for (equivalent to the second highest bid + an increment). item - Type of item.The table below shows the fields with some sample data:
auctionid bid bidtime bidder bidderrate openbid price item daystolive 8213034705 95 2.927373 jake7870 0 95 117.5 xbox 3 - Start the Spark interactive shell:
-
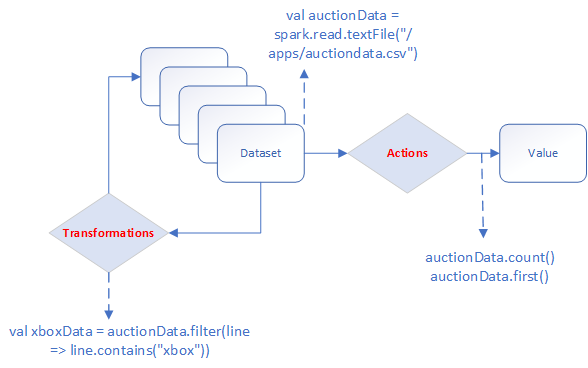
$SPARK_HOMErepresents the home of your Spark installation in MapR, for example:/opt/mapr/spark/spark-2.2.1/.$ $SPARK_HOME/bin/spark-shell --master local[2] - Once the Spark shell is ready, load the dataset:
val auctionData = spark.read.textFile("/apps/auctiondata.csv") - Display the first entry:
auctionData.first() - Count the number of entries:
auctionData.count() - Use other Spark actions:
// Displays first 20 lines auctionData.show() // Displays first 3 lines - change value to see more/less auctionData.take(3) - Transform the dataset into a new one that contains only
xboxlines, and count them:val auctionWithXbox = auctionData.filter(line => line.contains("xbox")) auctionWithXbox.count()- This could also be done in a single line by chaining transformations and actions:
auctionData.filter(line => line.contains("xbox")).count() - Use Spark Dataframes:
val auctionDataFrame = spark.read.format("csv").option("inferSchema", true).load("/apps/auctiondata.csv").toDF("auctionid","bid","bidtime","bidder","bidderrate","openbid","price","item","daystolive") - Use a
filtertransformation on the Dataframe:auctionDataFrame.filter($"price" < 30).show()
Writing Data from file system
Using the same dataset, save all xbox items as a file in file system:
- You can use the filter($"item" === "xbox") filter and
write.json or other options to save the result of the action to
file system.
auctionDataFrame.filter($"item" === "xbox").write.json("/apps/results/json/xbox")/apps/results/json/xbox directory in which
you will see the JSON file(s) created. You can use the same command to create Parquet or
any other file format:
auctionDataFrame.filter($"item" === "xbox").write.parquet("/apps/results/parquet/xbox")Writing Data to HPE Ezmeral Data Fabric Database JSON
The first step when you are working with HPE Ezmeral Data Fabric Database JSON
is to define a document _id that uniquely identifies the document.
Add a new _id field in the csv file and generate UUIDs to add to
this field.
dataframe.saveToMapRDB("tableName", createTable = true, bulkInsert = false, idFieldPath = "_id")The following commands will create a table and insert the data into:
/apps/auction_json_table.
import spark.implicits._
import java.util.UUID
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.SaveMode
import com.mapr.db.spark.sql._ // import the MapR-DB OJAI Connector
val generateUUID = udf(() => UUID.randomUUID().toString) // create UDF to generate UUID
// showing that you can create your own schema
val customSchema =
StructType(
Array(
StructField("actionid",StringType,true),
StructField("bid",DoubleType,true),
StructField("bidtime",DoubleType,true),
StructField("bidder",StringType,true),
StructField("bidderrate",IntegerType,true),
StructField("openbid",DoubleType,true),
StructField("price",DoubleType,true),
StructField("item",StringType,true),
StructField("daystolive",IntegerType,true)
)
) $ mapr dbshell
maprdb mapr:> find /apps/auction_json_table --limit 10Reading Data from HPE Ezmeral Data Fabric Database JSON
import com.mapr.db.spark.sql._
import org.apache.spark.sql.SparkSession
val dataFromMapR = spark.loadFromMapRDB("/apps/auction_json_table")
dataFromMapR.printSchema
dataFromMapR.count
dataFromMapR.filter($"price" < 30).show() // use a filter