Configuring Conda Python for Zeppelin
Describes how to configure Conda Python for Zeppelin.
The following steps assume that the miniconda distribution of Conda Python is already installed. For more information see the Conda documentation.
Use these steps:
- Create a Conda zip archive containing Python and all the libraries that you need. The following example creates a custom Conda environment with Python 2 and three packages (
matplotlib,numpy, andpandas):mkdir custom_pyspark_env conda create -p ./custom_pyspark_env python=2 numpy pandas matplotlib cd custom_pyspark_env zip -r custom_pyspark_env.zip ./The following example creates a custom Conda environment with Python 3 and three packages (matplotlib,numpy, andpandas):mkdir custom_pyspark3_env conda create -p ./custom_pyspark3_env python=3 numpy pandas matplotlib cd custom_pyspark3_env zip -r custom_pyspark3_env.zip ./IMPORTANTDo not create an archive namedpyspark.zip. This name is reserved for PySpark internals. - Upload the archive to the data-fabric file system. For example, if the archive name is
custom_pyspark_env.zip, and you want to put the archive in a directory that all users can read:hadoop fs -mkdir /apps/zeppelin hadoop fs -put custom_pyspark_env.zip /apps/zeppelin - Add the full path (including
maprfs://schema) to the archive intospark.yarn.dist.archive, and configure the Spark / Livy interpreter to use Python from this distribution.Note that all archives listed in the property will be extracted into a working directory of YARN application.
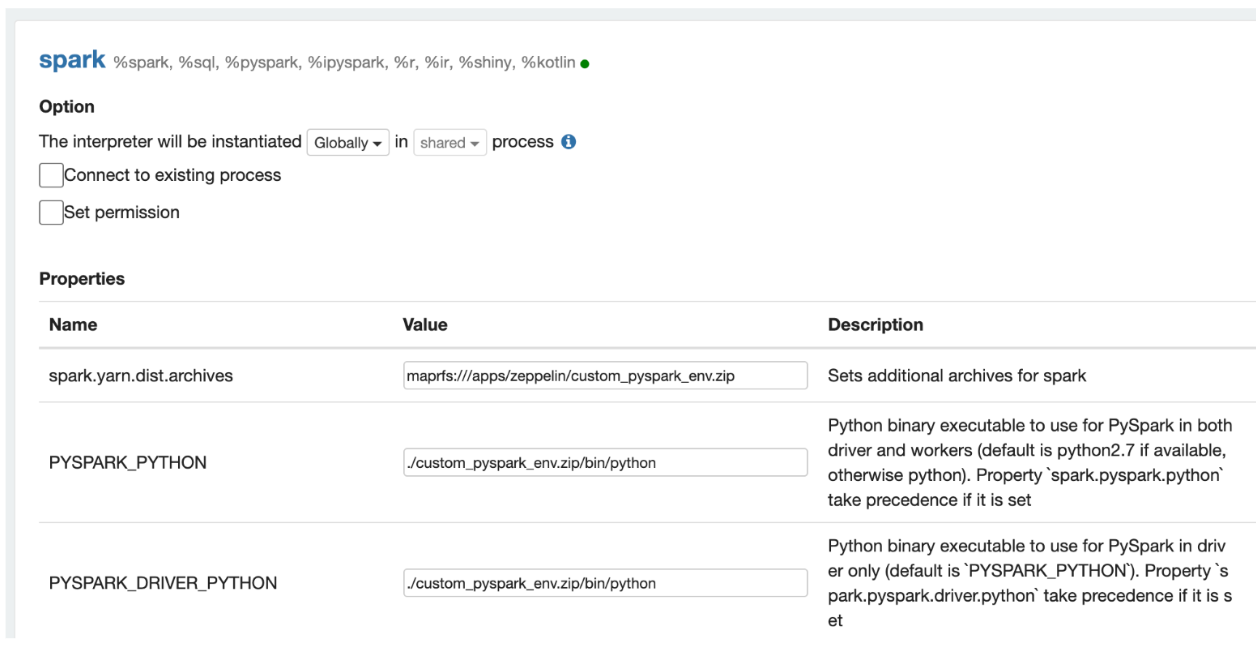
- For the Spark interpreter, set the PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON environment
variables (it can be done by configuring Spark interpreter):
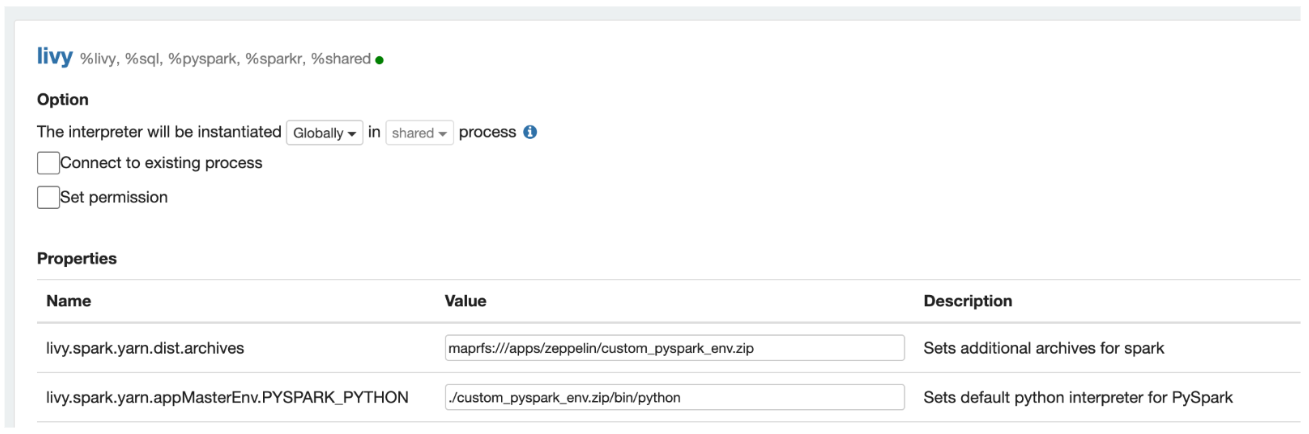
- For the Livy interpreter, set the
livy.spark.yarn.appMasterEnv.PYSPARK_PYTHONproperty: