Volumes, Snapshots, and Mirrors
Describes what Snapshots and Mirrors are, and the advantages of using them for replication.
Volumes are a management entity that logically organize a cluster’s data. Since a container always belongs to exactly one volume, that container’s replicas all belong to the same volume as well. Volumes do not have a fixed size and they do not occupy disk space until the Data Fabric file system writes data to a container within the volume. A large volume may contain anywhere from 50-100 million containers.
The CLI and REST API provide functionality for volume management. Typical use cases include volumes for specific users, projects, development, and production environments. For example, if an administrator needs to organize data for a special project, the administrator can create a specific volume for the project. The HPE Ezmeral Data Fabric file system organizes all containers that store the project data within the project volume. A cluster can have many volumes.
The HPE Ezmeral Data Fabric file system creates a name container for each volume. The name container stores the volume’s namespace and file chunk locations, along with inodes for the objects in the file system. The file system stores the metadata for files and directories in the name container, which is updated with each write operation.
The first 64KB of each file in a volume is written to the name container. Data beyond 64KB is written to data containers. Data containers are created only when the file or table data goes above 64KB. Each name or data container is associated with only one volume; volumes may have many associated data containers, but only one name container.
Local volumes are part of the cluster’s global namespace, and are accessible on the path
/var/mapr/local/<host>.
On a cluster with an Enterprise Edition or Enterprise Database Edition license, you can create a special type of volume called a mirror, a local or remote read-only copy of an entire volume. Mirrors are useful for load balancing or disaster recovery. You can also create a snapshot, an image of a volume at a specific point in time. Snapshots are useful for rollback to a known data set.
On a cluster, you can create a tenant share, or volume for tenant users. A tenant share is an isolated space where you can set different policies, quotas, and access privileges for specific users/hosts (referred to as tenants). This allows each tenant to own its own copy of storage space, users, data security, administration, and other such specifications. For more information, see Multitenancy on File System.
Snapshots
Snapshots enable you to roll back
to a known good data set
and recover data always in case
of data corruption or accidental deletions, without the help of storage administrators. A
snapshot is a read-only image of a volume that provides point-in-time recovery. Snapshots
only store changes to the data present in the volume, and as a result make extremely
efficient use of the cluster’s disk resources. Snapshots preserve access to historical data,
and protect the cluster from user and application errors. You can create a snapshot manually, or automate the process
with a schedule. Snapshots are stored in the .snapshots directory. You can
always view snapshots from this directory.
The following image represents a mirror volume, and a snapshot created from a source volume:
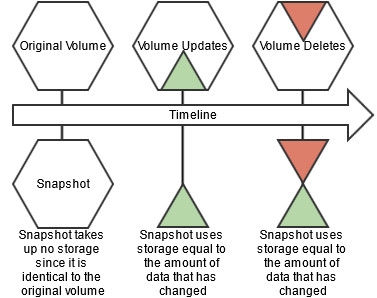
New write operations on a volume with a snapshot are redirected to preserve the original data. Snapshots only store the incremental changes in a volume’s data from the time the snapshot was created. The storage used by a volume's snapshots does not count against the volume's quota.
Mirror Volumes
Data Fabric provides built-in mirroring to set recovery time objectives and to automatically mirror data for backup. You can create local or remote mirror volumes to mirror data between clusters, data centers, or between on-premise and public cloud infrastructures.
Mirror volumes are read-only copies of a source volume. You can control the schedule for mirror refreshes from the Control System or with the command-line tools. You can create local (on the same cluster) or remote (on a different cluster) mirror volumes from the Control System, or from the command line.
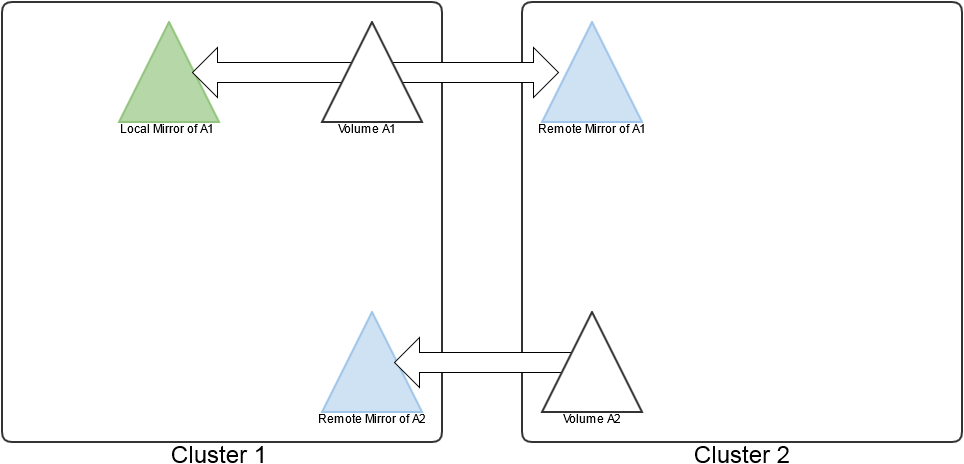
When you create a mirror volume, the HPE Ezmeral Data Fabric file system creates a temporary snapshot of the source volume. The mirroring process reads content from the snapshot into the mirror volume. The source volume remains available for read and write operations during the mirroring process. The initial mirroring operation copies the entire source volume. Subsequent mirroring operations only update the differences between the source volume and the mirror volume.
Mirror volumes can be promoted to read-write volumes. The main use case for this feature is to support disaster-recovery scenarios in which a read-only mirror needs to be promoted to a read-write volume so that it can become the primary volume for data storage. In addition, read-write volumes that were mirrored to other volumes can be made into mirrors (to establish a mirroring relationship in the other direction). You can also convert read-write volumes back to read-only mirrors.