Restoring a Volume From a Snapshot
Provides a synopsis of restoring a volume from a snapshot. Describes the implications, and the prerequisites.
For an introduction to Snapshots, see Volumes, Snapshots, and Mirrors.
To create snapshots, see Creating Volume Snapshots.
High Level Functionality
When files are accidentally deleted or data inside a volume is corrupted, you must manually restore older data from an earlier snapshot by creating a new volume and copying data from the snapshot.
For example, consider a volume with the following snapshots:

To restore from snapshot S3, you need to first create a new volume and then copy over data from snapshot S3, as shown:
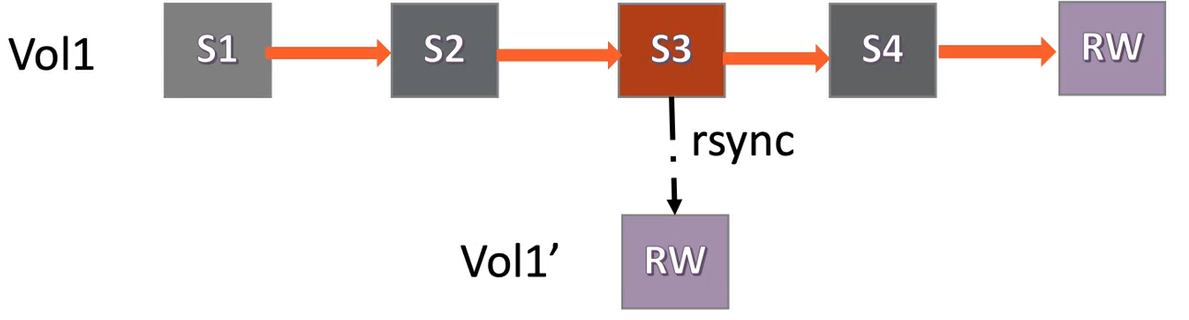
- Being unable to meet the SLAs of restoring snapshots in under 10 minutes, because of the time taken to do the copying file by file.
- Data duplication and wasted space consumption, because snapshots after the restored snapshot, are retained (snapshot S4 in this example).
The snapshot restore functionality has the capability to restore an entire volume to a point-in-time snapshot. The snapshots taken prior to the one that has been restored to, are retained and snapshots taken after the one that has been restored to, are deleted. The data prior to the restored snapshot remains intact, and only the data newer to the restored snapshot is deleted.
For example, consider a volume with the following snapshots:

To restore from snapshot S3, first delete snapshots S4 and S5, as shown:
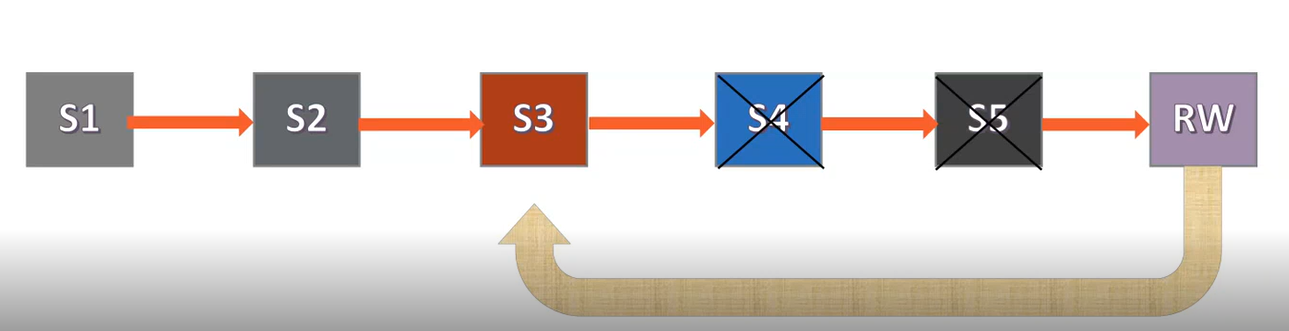
The snapshot S3 is then pointed over to the current RW volume.

This optimization speeds up the restore operation when compared to manually copying the data to a new volume.
For another example, assume that volume vol1 has a daily snapshot
schedule and currently has 7 snapshots ss1, ss2,
ss3, ss4, ss5,
ss6 and ss7. ss1 is the oldest
snapshot, while ss7 is the most recent snapshot.
The snapshot restore functionality allows you to restore vol1 to a
snapshot, say ss5. After vol1 is restored, snapshots
ss6, and ss7 are automatically deleted.
You can take additional snapshots on vol1, say snapshots
ss8, ss9 and ss10, and restore
vol1 to any earlier snapshot.
Salient Features of Snapshot Restore
- Is almost instantaneous
- Uses minimum or no network/disk IO
- Works across all volume types including tiering-enabled, RW and mirror volumes. Works with HPE Ezmeral DB tables without secondary indexes as well
- Uses ACID semantics (recovers on node reboots)
- Is parallel and distributed
- Permits access to older snapshots during operation
- Has zero down-time
- Gracefully handles timeouts, retries and failures
- Does not hinder normal user operations
Advantages of Snapshot Restore
- Quickly restore a volume if files get corrupted or accidentally deleted.
- Periodically add modifications to a snapshot's data and use it as a mirror volume to sync the current RW source when needed.
Considerations to Use Snapshot Restore
Restoring a volume from an earlier snapshot is a disruptive operation. Thousands of Hadoop applications may be running on the cluster at any given time, and are likely to be impacted. When restoring from an earlier snapshot, some recent data may be lost. The Data Fabric cluster administrator must therefore consider the following implications, before restoring a snapshot.
- To ensure data consistency, by default, the volume restore operation is allowed only
if the volume is unmounted, ensuring that no application is accessing any data in the
volume. See Unmounting one or more Volumes.
You can override this behaviour by setting
cldb.snapshot.restore.on.volume.unmount.onlyto0.To check the current value of this setting, run:
/opt/mapr/bin/maprcli config load -json | grep cldb.snapshot.restoreSet this flag to
0to perform the restore operation in a single step, without verifying whether the volume is unmounted or not. To set this flag to0, run:/opt/mapr/bin/maprcli config save -values '{"cldb.snapshot.restore.on.volume.unmount.only":"0"}' -jsonYou may encounter the following issues, if the volume is not unmounted:
- Stale (ESTALE) errors as files might get deleted, truncated or modified.
- Inconsistent or wrong results as subset of containers might not yet get restored.
- Client crashes due to the ongoing restore operation.
- In addition to files and directories, a volume can contain database tables,
secondary indices for tables, and Kafka topics. If you are restoring a volume that
contains one or more of these additional entities, you need to understand the
following implications:
- Tables and their associated secondary indices may be out of sync after a
restore from snapshot operation. OJAI or Drill queries that retrieve data from
tables (that reside on the restored volume) do not use secondary indices.
Therefore, queries use full table scan, and may take longer to complete. To leverage secondary indices during query execution, the Data Fabric cluster administrator must re-create the secondary indices that reside on the volume. Refer to Re-enabling a Volume for Secondary Indices and Replication after Restoring From a Snapshot for details.
- Tables (across volumes or cluster) may have been setup with multi master
replication.
When a volume is restored from an earlier snapshot, the replication relationship is broken between the tables.
The Data Fabric cluster administrator must re-establish the replication relationship. Refer to Re-enabling a Volume for Secondary Indices and Replication after Restoring From a Snapshot for details. - Topics (across clusters) may have been setup with global replication.
When a volume is restored from an earlier snapshot, the replication relationship is broken between the topics.
The Data Fabric cluster administrator must re-establish the replication relationship. Refer to Re-enabling a Volume for Secondary Indices and Replication after Restoring From a Snapshot for details.
- For change data capture, the replication to the destination Data Fabric ES stream topic is stopped. However, the
stream is preserved.
The Data Fabric cluster administrator must create a new Data Fabric Table to ES topic relationship after the Snapshot Restore operation is complete.
- Tables and their associated secondary indices may be out of sync after a
restore from snapshot operation. OJAI or Drill queries that retrieve data from
tables (that reside on the restored volume) do not use secondary indices.
- The volume level Access Control Expression (ACE)s
are restored to the values which were set at the time of creation of snapshot to
which the volume is being restored.
The file level tagging done for Policy Based Security (PBS) is reverted to the point of time of the snapshot to which the volume is being restored.
- Only one snapshot restore operation can be in progress at a time for a given volume.
Use the
snapshot restorestatuscommand to check the status of the snapshot restore operation.If a second snapshot restore operation is initiated before the first operation is complete, the second snapshot restore operation is queued.
- You need to have
FullControlaccess on the volume to perform the snapshot restore operation. Refer to Volume ACLs for information on access controls. - Snapshot restore functionality can be performed only if the following conditions are
met:
- Snapshots should be at a minimum of version 6.2 to be restored, which means that you need to create a snapshot after installing Data Fabric version 6.2.
- Volumes must be of type
Standard Volume (rw)orStandard Mirror (mirror)(which can be created from MapR version 4.0.2 onwards). For a complete list of volume types, refer Types of Volumes.If volumes are not of the type specified, run the upgrade utility on older volumes, and then use the snapshot restore functionality. For details on the upgrade utility, refer maprcli volume upgradeformat.
- Operations such as mirroring, offload, and tiering should not be in progress on the volume where the snapshot restore is in progress. These operations fail if performed when the snapshot operation is in progress.
- The volume being considered for the snapshot operation should not be an internal volume. Snapshot restore operation is allowed only on standard, tiering, and mirror volumes.
- The Snapshot Restore operation takes precedence over all other operations. For example, if a tiering operation is in progress, when a Snapshot Restore operation is requested, the tiering operation is paused, and the Snapshot Restore operation is performed. The tiering operation is resumed after the Snapshot Restore operation is complete.
- When restoring a snapshot that does not contain child volumes over a volume that does contain child volumes, the child volumes are preserved, but the volume links are not preserved. You need to relink the child volumes once the Snapshot Restore operation is complete.
- At a container level:
- Any ongoing resync operation is aborted.
- The Snapshot Restore operation is optimized to skip if there are no new versions in RW when compared to the snapshot.
Re-enabling a Volume for Secondary Indices and Replication after Restoring From a Snapshot
Restoring a volume from an earlier snapshot, permanently stops all operations such as updating secondary indices, replication between source and destination tables, until you configure a new relationship. Administrators need to note the following implications of restoring a volume from a snapshot.
- Volume is restored to a point of snapshot.
- Ongoing operations of Secondary Indices and Table replication fail
To re-enable a volume for secondary indices and replication, administrators must delete existing relationships, and recreate them.
Effects of Snapshot Restore
- On Object Tiering
- All tiering operations continue to work smoothly after Snapshot Restore is complete.
- Offloaded data from newer snapshots are purged as part of compaction.
- On Mirrors
- Data on the destination volume is purged in a subsequent resync operation if Snapshot Restore occurs on the source volume.
- The destination volume always reconciles to the source volume on a subsequent resync operation after every Snapshot Restore operation. You can preserve the changes by taking a snapshot on the mirror.
- On Table Replication and Secondary Indices
- Snapshot Restore on the source volume makes replicas and secondary indices go out of sync.
- All operations from source to replica or secondary indices are permanently stopped.
- Administrators must delete existing relationships and reconfigure them,
- Table replications fail and the table replication errors alarm is raised as expected.
Enabling Snapshot Restore on an Upgraded Cluster
The Snapshot Restore operation is enabled by default on a new Data Fabric version 6.2 cluster.
maprcli cluster feature enable -name mfs.feature.snapshot.restore.support -force trueRelated Alarms
The Snapshot Restore operation is retried indefinitely till it succeeds. However, the
VOLUME_ALARM_SNAPRESTORE_MAXRETRIES_EXCEEDED alarm is raised if the
snapshot restore operation failed and has been retried for more than five (5) times for
a single container.
For more information, see VOLUME_ALARM_SNAPRESTORE_MAXRETRIES_EXCEEDED.
Related Log Files
Administrators can view the following events and logs for troubleshooting.
- Start and end of volume level snapshot restore (cldb.log)
- Removal of intermediate snapshots (cldb.log)
- Any failures or retries (both cldb.log and mfs.log)
- Start and end of container level snapshot restore (mfs.log)
- Container level operation already in progress (mfs.log)
- Snapshot and RW are on the same version and no Snapshot Restore operation is needed (mfs.log)
- Message if container level operation takes longer than the threshold time at MFS (mfs.log)
Control System
Refer to Restoring Volume Snapshots Using the Control System to restore snapshots using the Control System.
CLI Commands
Refer to the following CLI commands, to restore a volume from a snapshot: