Understanding the HPE Ezmeral Data Fabric Database OJAI Connector for Spark
Using the HPE Ezmeral Data Fabric Database OJAI connector for Spark enables you build real-time and batch pipelines between your data and HPE Ezmeral Data Fabric Database JSON. Before getting started, it is important that you understand Spark terminology and workflow, system requirements and support, and OJAI connector and API features.
The HPE Ezmeral Data Fabric Database OJAI connector includes a set of APIs that enable you to write applications that consume HPE Ezmeral Data Fabric Database JSON tables and use them in Spark. The HPE Ezmeral Data Fabric Database OJAI Connector for Apache Spark is a companion to the HPE Ezmeral Data Fabric Database Binary Connector for Apache Spark, which provides the equivalent functionality for HPE Ezmeral Data Fabric Database Binary tables.
HPE Ezmeral Data Fabric Database OJAI Connector with Spark Workflow
You can use the HPE Ezmeral Data Fabric Database OJAI Connector to extract data from
HPE Ezmeral Data Fabric Database or file system and
transform that data using either Spark or Spark SQL, and then load it into HPE Ezmeral Data Fabric Database JSON: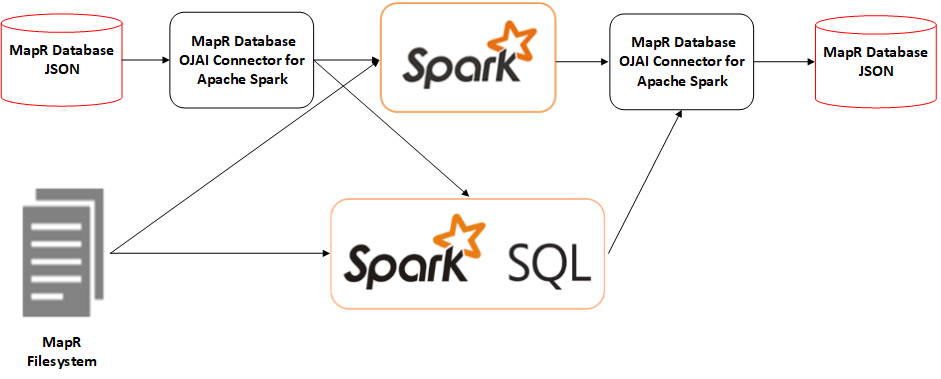
HPE Ezmeral Data Fabric Database OJAI Connector for Apache Spark Features
Principal features of the HPE Ezmeral Data Fabric Database OJAI Connector for Apache Spark include the following:
- Support for Scala and, beginning with EEP 4.1,
Java and Python APIs This matrix shows the programming languages and features supported:
Scala Java Python RDD Yes Yes No DataFrame Yes Yes Yes Dataset Yes Yes No DStream Yes No No - APIs that enable you to load data from a HPE Ezmeral Data Fabric Database JSON table to an Apache Spark RDD, DataFrame, or Dataset
- Projection and filter pushdown for better performance
- Custom partitioner for RDDs that enables you to partition data for better performance
- APIs that save an Apache Spark RDD, DataFrame, or DStream to a HPE Ezmeral Data Fabric Database JSON table using either normal or bulk insert
- Support for Scala and Java bean classes
- Support for data locality
- Support for secondary indexes starting from EEP 7.0.0 and EEP 6.3.1.
The following features are not supported:
- HPE Ezmeral Data Fabric Database Binary tables
Only HPE Ezmeral Data Fabric Database JSON tables are supported; access to HPE Ezmeral Data Fabric Database binary tables is provided through the HPE Ezmeral Data Fabric Database Binary Connector.
- Secondary indexes are not suported for previous EEP 7.0.0 and EEP 6.3.1 versions.
Supported Product Versions and System Requirements
To use the HPE Ezmeral Data Fabric Database OJAI Connector for Apache Spark, you must have the following minimum software versions:
- MapR: 5.2.1 or later
- EEP 3.0 or later
- Spark 2.1.0 or later
- Scala 2.11 or later
- Java 8 or later
OJAI API
The HPE Ezmeral Data Fabric Database OJAI Connector for Apache Spark uses the OJAI API internally to access HPE Ezmeral Data Fabric Database JSON tables.