Saving an Apache Spark DStream to a HPE Ezmeral Data Fabric Database JSON Table
The HPE Ezmeral Data Fabric Database OJAI Connector for Apache Spark enables you to use HPE Ezmeral Data Fabric Database as a sink for Apache Spark DStreams.
NOTE
Saving of Apache Spark DStream to HPE Ezmeral Data Fabric Database JSON table is currently only supported in
Scala.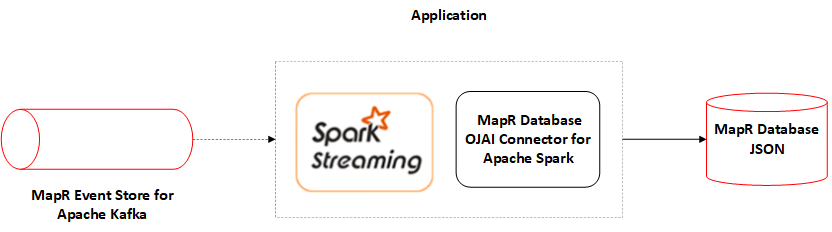
The following API saves a DStream[OJAIDocument] object to a HPE Ezmeral Data Fabric Database
table:
def saveToMapRDB(tablename: String, createTable: Boolean,
bulkInsert: Boolean, idFieldPath: String): UnitThe parameters are as follows:
| Parameter | Default | Description |
tableName |
Not applicable | The name of the HPE Ezmeral Data Fabric Database table to which you are saving the DStream. |
createTable |
false |
Creates the table before saving the DStream. Note that if the table already exists
and createTable is set to true, the API throws an exception. |
idFieldPath |
_id |
Specifies the key to be used for the DStream. |
bulkInsert |
false |
Loads a group of streams simultaneously. bulkInsert is similar to
a bulk load in MapReduce. |
NOTE
The only required parameter for this function is tableName. All the others are optional.The following example creates a DStream object, converts it to a
DStream[OJAIDocument] object, and then stores it in
HPE Ezmeral Data Fabric Database:
val clicksStream: DStream[String] = createKafkaStream(…)
clicksStream.map(MapRDBSpark.newDocument()).saveToMapRDB("/clicks", createTable=true)NOTE
You must use the map(MapRDBSpark.newDocument()) API to convert the DStream
object to a DStream[OJAIDocument] object.If
clicksStream is a DStream of Strings, it can be saved to HPE Ezmeral Data Fabric Database using
the saveToMapRDB API:
clicksStream.map(MapRDBSpark.newDocument(_)).saveToMapRDB("/clicks", createTable = true);NOTE
To use the saveToMapRDB API, you need to transform the DStream object to a
DStream[OJAIDocument] by using the Apache Spark Map API.