High Availability
High availability (HA) in deployments of HPE Ezmeral Runtime Enterprise is divided into platform controller HA, gateway HA, and cluster HA.
Different types of high availability (HA) protection are available:
- Platform High Availability. This protection applies to HPE Ezmeral Runtime Enterprise Controller and services.
- Gateway Host High Availability. This protection applies to the Gateway hosts.
- Kubernetes Cluster High Availability. This protection applies to all Kubernetes clusters.
Platform High Availability
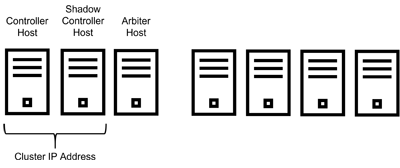
Platform high availability protects against the failure of the Controller host. When Platform HA is enabled, three different hosts are used:
- The Controller host
- The Shadow Controller host
- The Arbiter host
Under normal circumstances:
- The Controller host manages HPE Ezmeral Runtime Enterprise.
If any of the three hosts fails, the following actions occur:
-
Host-specific failure actions:
- Controller host failure
-
If the Controller host fails, the Arbiter host switches management to the Shadow Controller host. This process usually takes two to three minutes. After a failover to the Shadow Controller host, the deployment continues to run, but in a degraded state. In that degraded state, there is no protection against the failure of the Shadow Controller host.
During a failover, all user web sessions will be terminated. Users must sign in again after the failover process completes.
- Shadow Controller host failure
-
If the Shadow Controller host fails but the Controller host is running, the deployment continues to run, but in a degraded state. In that degraded state, there is no protection against the failure of the Controller host.
- Arbiter host failure
-
If the Arbiter host fails but the Controller host is running, the deployment continues to run, but in a degraded state. In that degraded state, there is no protection against a Controller host failure. Failover to the Shadow Controller cannot occur if the Arbiter host has failed.
-
A message is displayed in the upper right corner of the web interface warning you that the deployment is running in a degraded state. If the Shadow Controller or Arbiter host fails, the message is displayed even if the Controller host is functioning properly.
If SNMP/SMTP is configured, service alerts are sent.
You can use the Service Status tab of the Platform Administrator Dashboard (see Dashboard - Platform Administrator) to see which host has failed and which services are down.
- HPE Ezmeral Runtime Enterprise analyzes the root cause of the host failure and attempts to recover the failed host automatically. If recovery is possible, the failed host comes back up, and normal operation resumes.
-
If the problem cannot be resolved, the affected host is left in an error state.
You must manually diagnose and repair the problem (if possible) and then reboot that host. If rebooting solves the problem, then the failed host will come back up, and normal operation will resume. If rebooting the host does not solve the problem, contact Hewlett Packard Enterprise Support for assistance.
Each host has its own IP address. If the Controller host fails, attempting to access the Shadow Controller host using the same IP address will fail. Similarly, accessing the Shadow Controller host using that host IP address will fail after the Controller host recovers. To avoid this problem, you must do one of the following:
-
Access the web interface using one of the following:
- If configured, you can use the host name of the Gateway host or Gateway set (if there are multiple Gateway hosts).
- If configured when HA was enabled, you can use the cluster host name.
- You can use the IP address, without a port number, of any Gateway host.
-
Specify a cluster IP address that is bonded to the node acting as the Controller host, and then sign into the web interface using that cluster IP address. You will automatically connect to the Controller host (under normal circumstances) or to the Shadow Controller host with a warning message (if the Controller host has failed and triggered the High Availability protection). In this case, the Primary Controller and Shadow Controller hosts must be on the same subnet. You can access the web interface by using either the cluster IP address or a Gateway host IP address.
Gateway Host High Availability
You can add redundancy for Gateway hosts by mapping multiple Gateway host IP addresses to a single hostname. When this mapping is done, then either the DNS server or an external load balancer will load-balance requests to the hostname among each of the Gateway hosts on a round-robin basis. This configuration ensures that there is no single point of failure for the Gateway host. For more information, see The Gateway/Load Balancer Screen.
Kubernetes Cluster High Availability
You provide High Availability protection for a Kubernetes cluster by configuring a minimum of three hosts as the Kubernetes control plane (formerly called Kubernetes "masters"). You can specify additional control plane hosts, in odd number increments, for additional HA protection.
In Kubernetes, the state of the cluster is stored in a distributed key-value data store called etcd. Kubernetes clusters created by HPE Ezmeral Runtime Enterprise use kubeadm tools and a stacked controller etcd topology. In a stacked controller etcd topology, there is an instance of etcd in each control plane node.
Because of quorum requirements for etcd, two Kubernetes cluster control plane hosts are not sufficient. Although an even number of Kubernetes control plane nodes is supported for situations such as migrating a cluster, To maintain a quorum, HPE Ezmeral Runtime Enterprise recommends that you configure an odd number of Kubernetes control plane nodes.
Clusters with an even number of control plane nodes risk losing quorum permanently with a so-called "split brain." For example, consider a three-node Kubernetes control plane in which one node is down. The cluster can continue to operate because the quorum is two nodes. However, if you expand the control plane to four nodes, the quorum becomes three nodes. If you add the fourth node while one node remains down, and the addition of the fourth node fails because of an error, quorum is permanently lost: Your four-node control plane now has two nodes up and two nodes down, but requires a majority of three nodes to undo the failed membership change.
For more information about quorums, failure tolerance, and etcd clusters, see Failure Tolerance in the etcd documentation (link opens an external website in a new browser tab or window).