Using Spark to Query EzPresto
Describes how to use Spark to query EzPresto.
Using Spark to Query EzPresto with the EzPresto Plugin
The EzPresto plugin retrieves and processes vast datasets quickly and efficiently, making it suitable for large-scale data operations. The Spark images packaged with HPE Ezmeral Unified Analytics Software include the Presto client library. The Presto client library is required to connect Spark to EzPresto. When you connect Spark to EzPresto, you do not have to explicitly provide a username and password because the bundled EzPresto client library automatically sets and manages credential renewal.
Spark runtimes do not have the EzPresto
certificate in the truststore. When you connect Spark to EzPresto, you must set the
ignore_ssl_check option to true.
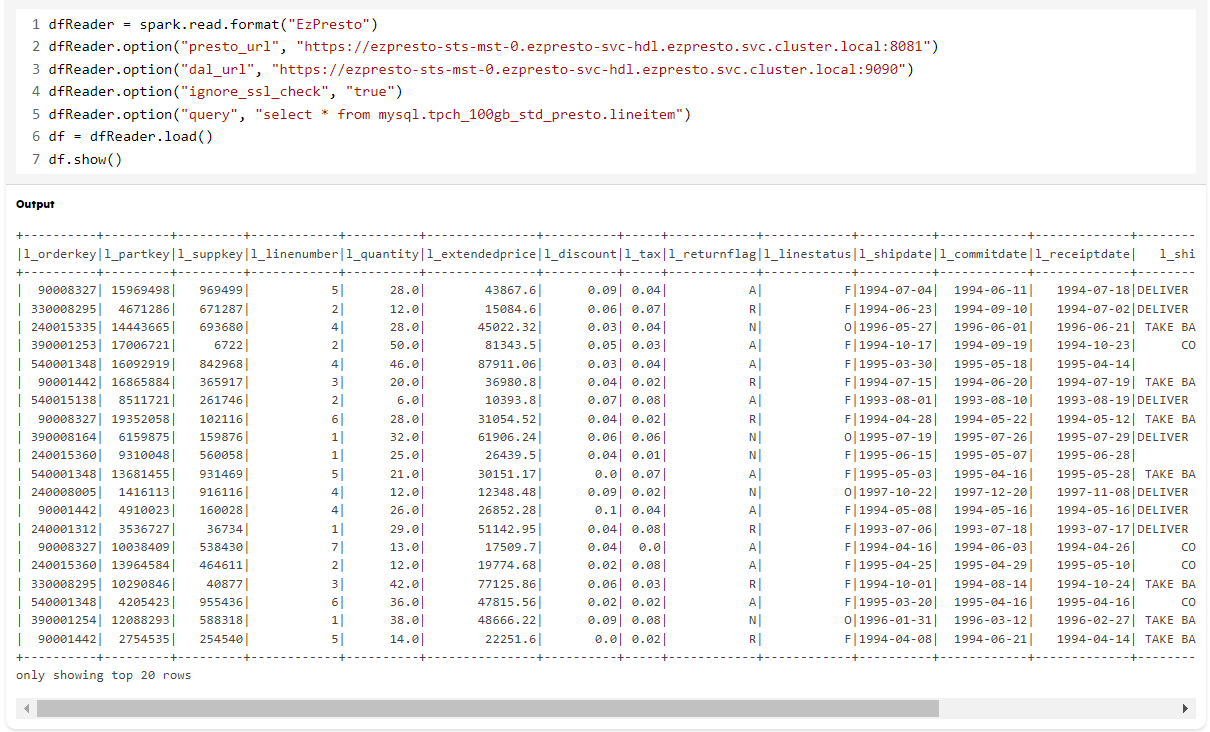
dfReader = spark.read.format("EzPresto")
dfReader.option("presto_url", "https://ezpresto-sts-mst-0.ezpresto-svc-hdl.ezpresto.svc.cluster.local:8081")
dfReader.option("dal_url", "https://ezpresto-sts-mst-0.ezpresto-svc-hdl.ezpresto.svc.cluster.local:9090")
dfReader.option("ignore_ssl_check", "true")
dfReader.option("query", "select * from mysql.tpch_100gb_std_presto.lineitem")
df = dfReader.load()
df.show()
val query = "select * from mysql.tpch_100gb_std_presto.lineitem"
val dfReader = spark.read.format("EzPresto")
dfReader.option("presto_url", "https://ezpresto-sts-mst-0.ezpresto-svc-hdl.ezpresto.svc.cluster.local:8081")
dfReader.option("dal_url", "https://ezpresto-sts-mst-0.ezpresto-svc-hdl.ezpresto.svc.cluster.local:9090")
dfReader.option("ignore_ssl_check", "true")
dfReader.option("query", query)
val df = dfReader.load()
df.show()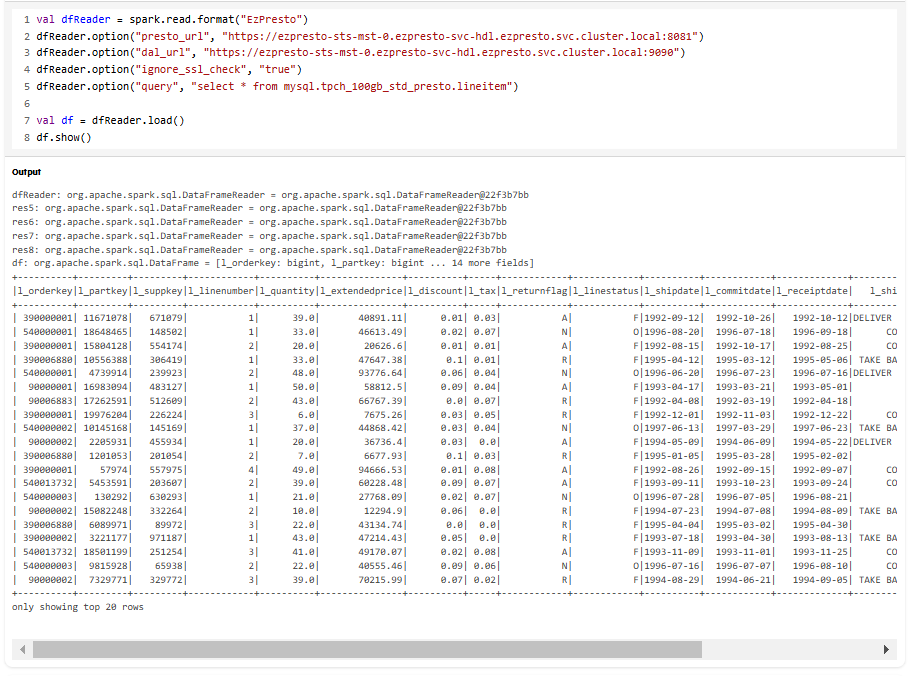
Using Spark to Query EzPresto via Legacy Method
Spark images packaged with HPE Ezmeral Unified Analytics Software include the Presto client library required to connect Spark to EzPresto.
Spark runtimes do not have the EzPresto
certificate in the truststore; therefore, when you connect Spark to EzPresto, you must set
the IgnoreSSLChecks option to true.
For open-source Spark use cases, the CA certificate must be available in the JVM
truststore. You can set a custom path to the truststore using the jdbc
SSLTrustStorePath option. Note that you must use JKS format.
DOMAIN = "<your-unified-analytics-domain-name>"
user = "<username>"
catalog = "mysql"
table = "tpch_100gb_std_presto"
uri = f"jdbc:presto://ezpresto.{DOMAIN}:443/{catalog}/{table}"
query = "select * from mysql.tpch_100gb_std_presto.lineitem"
df = spark.read.format("jdbc"). \
option("driver", "com.facebook.presto.jdbc.PrestoDriver"). \
option("url", uri). \
option("user", user). \
option("SSL", "true"). \
option("IgnoreSSLChecks", "true"). \
option("query", query). \
load().show()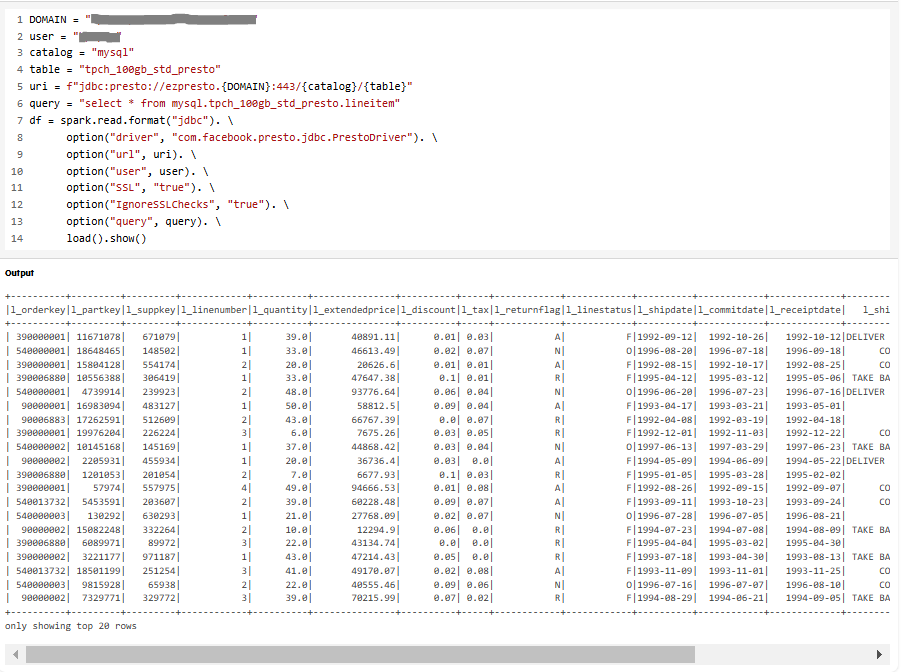
val DOMAIN = "<your-unified-analytics-domain-name>"
val user = "<username>"
val catalog = "mysql"
val table = "tpch_100gb_std_presto"
val uri = s"jdbc:presto://ezpresto.$DOMAIN:443/$catalog/$table"
val query = "select * from mysql.tpch_100gb_std_presto.nation"
val df = spark.read.format("jdbc").
option("driver", "com.facebook.presto.jdbc.PrestoDriver").
option("url", uri).
option("user", user).
option("SSL", "true").
option("IgnoreSSLChecks", "true").
option("query", query).
load().show()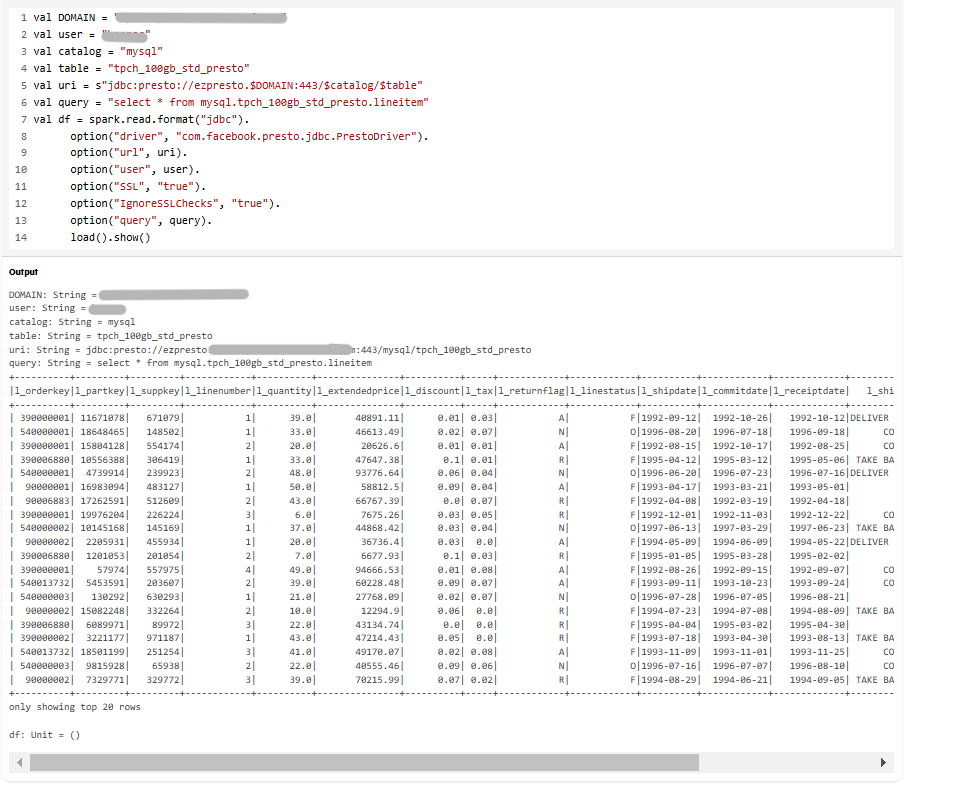
Limitations
- Does not support write operations.
- Does not support queries that require ordering of results, such as sort by or order by queries. While the query does not fail, the ordering is not maintained.
- You must always use aliases in SQL aggregations to ensure proper functionality. For
example, replace
COUNT()withCOUNT() AS col_name.