Connecting to CSV and Parquet Data in an External S3 Data Source via Hive Connector
Describes how to use the Hive connector with Presto in HPE Ezmeral Unified Analytics Software to connect to CSV and Parquet data in S3-based external data sources.
You can connect HPE Ezmeral Unified Analytics Software to any external S3-based data source through the Hive connector and Presto to access CSV and Parquet data. For example, you can connect HPE Ezmeral Unified Analytics Software to an external Data Fabric, Iceberg, or Spark cluster to access CSV and Parquet data in S3 storage within these data sources.
Connection Requirements
- You must have read/write access on the S3 data source.
- You must provide the required information to connect, including the:
- Access key
- Secret key
- S3 directory where files are stored
- S3 endpoint
For more information about the PrestoDB Hive connector, see Hive Connector.
Connecting to an S3-Based Data Source
To connect to an S3-based data source:
- Sign in to HPE Ezmeral Unified Analytics Software.
- In the left navigation bar, select Data Engineering > Data Sources.
- On the Structured Data tab, click Add New.
- In the Hive tile, click Create Connection.
- In the drawer that opens, enter values in the required fields. An asterisk (*) denotes a
required field.
- For Hive Metastore, select Discovery.
- In the Optional Fields search field, find and add the following fields:
Field Name Description Hive S3 AWS Access Key Enter the AWS access key. Hive S3 AWS Secret Key Enter the AWS secret key. Hive S3 Endpoint Enter the S3 endpoint. Hive S3 Path Style Access Select the checkbox.
- Click Connect. Upon successful connection, the data source is available on the
Data Sources page. TROUBLEIf the connection fails, see Hive Data Source Connection Failure (S3-Based External Data Souce).
- In the left navigation bar, select Data Engineering > Data Sources.
- In the data source tile, click Query using Data Catalog to access the S3 data.
- On the Data Catalog page, identify the data source and select the schema to view the data.
Example: Connect to HPE Ezmeral Data Fabric Object Store to access Parquet files
In this example, a bucket named prestodemo exists in HPE Ezmeral Data Fabric Object Store. Inside the bucket is a tpch002 directory with nation and nationalhistory sub-directories that contain Parquet files.
The following image shows the HPE Ezmeral Data Fabric Object Store prestodemo bucket and directories within the bucket: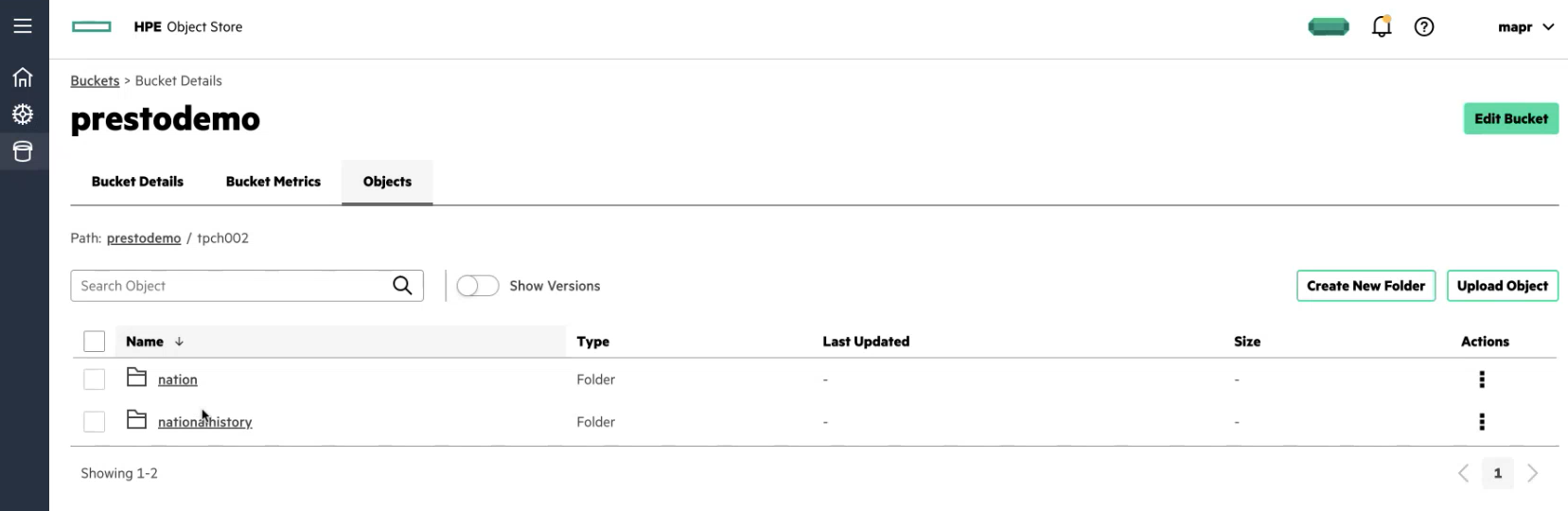
- Access key
- Secret key
- S3 directory where files are stored (Example:
s3://prestodemo/tpch002) - S3 endpoint (This is the HPE Ezmeral Data Fabric Object Store IP address and port, for example:
https://10.10.10.100:9000
To connect HPE Ezmeral Unified Analytics Software to an S3 Directory in an external HPE Ezmeral Data Fabric Object Store:
- Sign in to HPE Ezmeral Unified Analytics Software.
- In the left navigation bar, select Data Engineering > Data Sources.
- On the Structured Data tab, click Add New.
- In the Hive tile, click Create Connection.
- In the drawer that opens, complete the required fields:TIP
- In the drawer, search for and add the fields you do not see. Use the search field under Optional Fields to find and add these fields.
- No external Hive Metastore is required; HPE Ezmeral Unified Analytics Software internally parses and scans the files to get the data types and metadata.
Field Name Example Notes Name demoparquet Unique name for the data source connection. Hive Metastore Discovery System scans files to discover metadata and data types. Data Dir s3://prestodemo/tpch002 S3 directory where files are stored. File Type Parquet You can select Parquet or CSV depending on the type of data in the S3 directory. Hive S3 AWS Access Key The access key generated by the Data Fabric Object Store. Under Optional Fields, search for this field in the search box and select it. Hive S3 AWS Secret Key The secret key generated by the Data Fabric Object Store. Under Optional Fields, search for this field in the search box and select it. Hive S3 Endpoint https://10.10.10.100:9000 The Data Fabric Object Store connection URL. Under Optional Fields, search for this field in the search box and select it. Hive S3 Path Style Access Select the checkbox. Under Optional Fields, search for this field in the search box and select it. - Click Connect. The system displays the message,
"Successfully added data source,"and the new data source (demoparquet) tile appears on the Data Sources page.TROUBLEIf the connection fails, see Hive Data Source Connection Failure (S3-Based External Data Souce).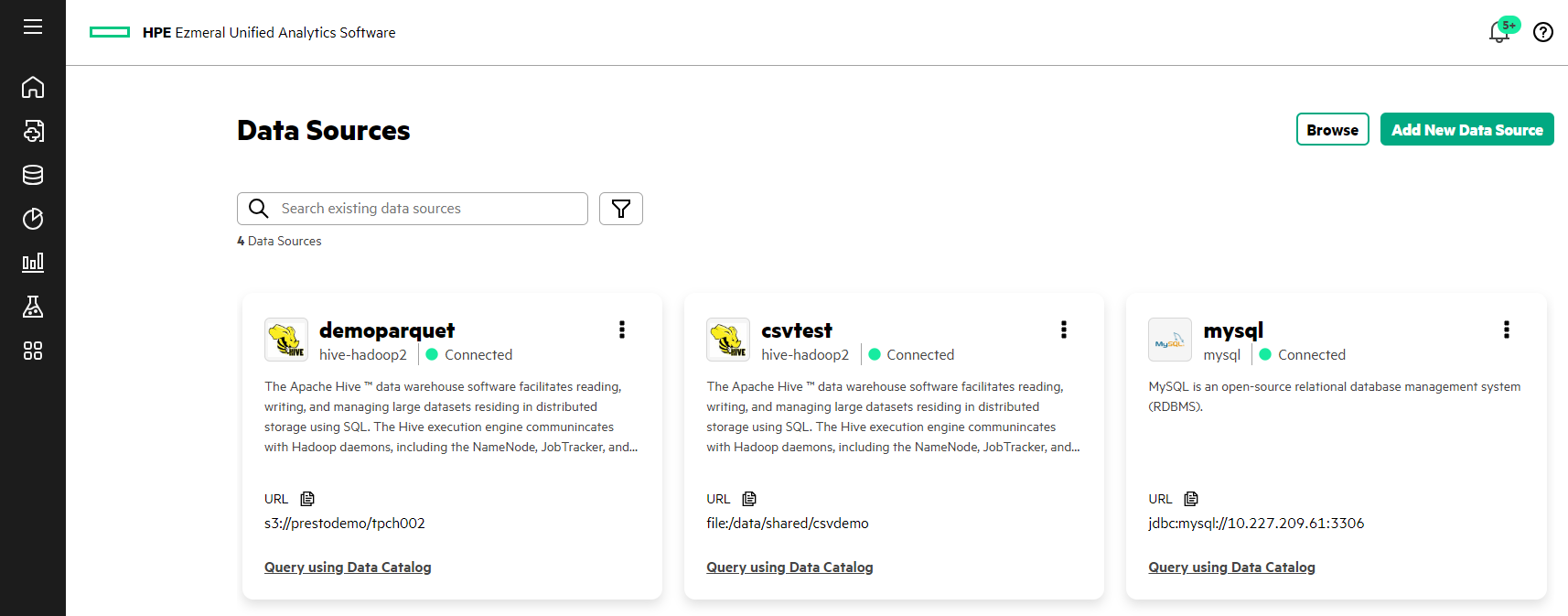
- In the new data source tile (demoparquet), click Query using Data Catalog.
You can see the
demoparquetsource listed.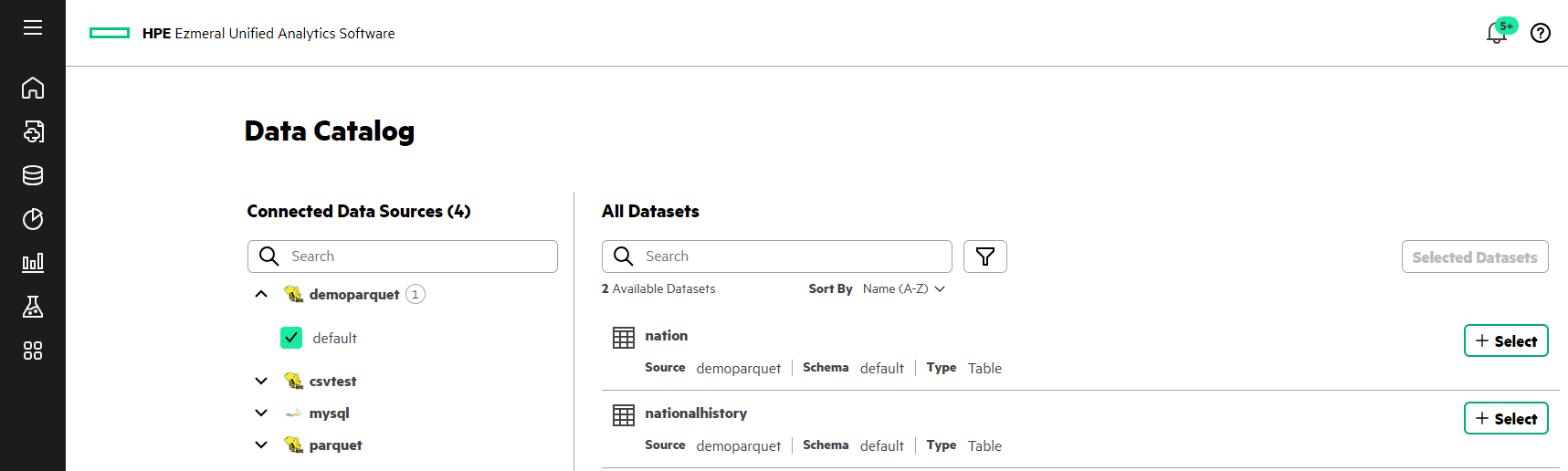
- Select the schema (default) under the data source to view the data
sets.NOTEEach subdirectory in the S3 directory displays as a table in HPE Ezmeral Unified Analytics Software, and each Parquet file in the subdirectory is a row in the table.
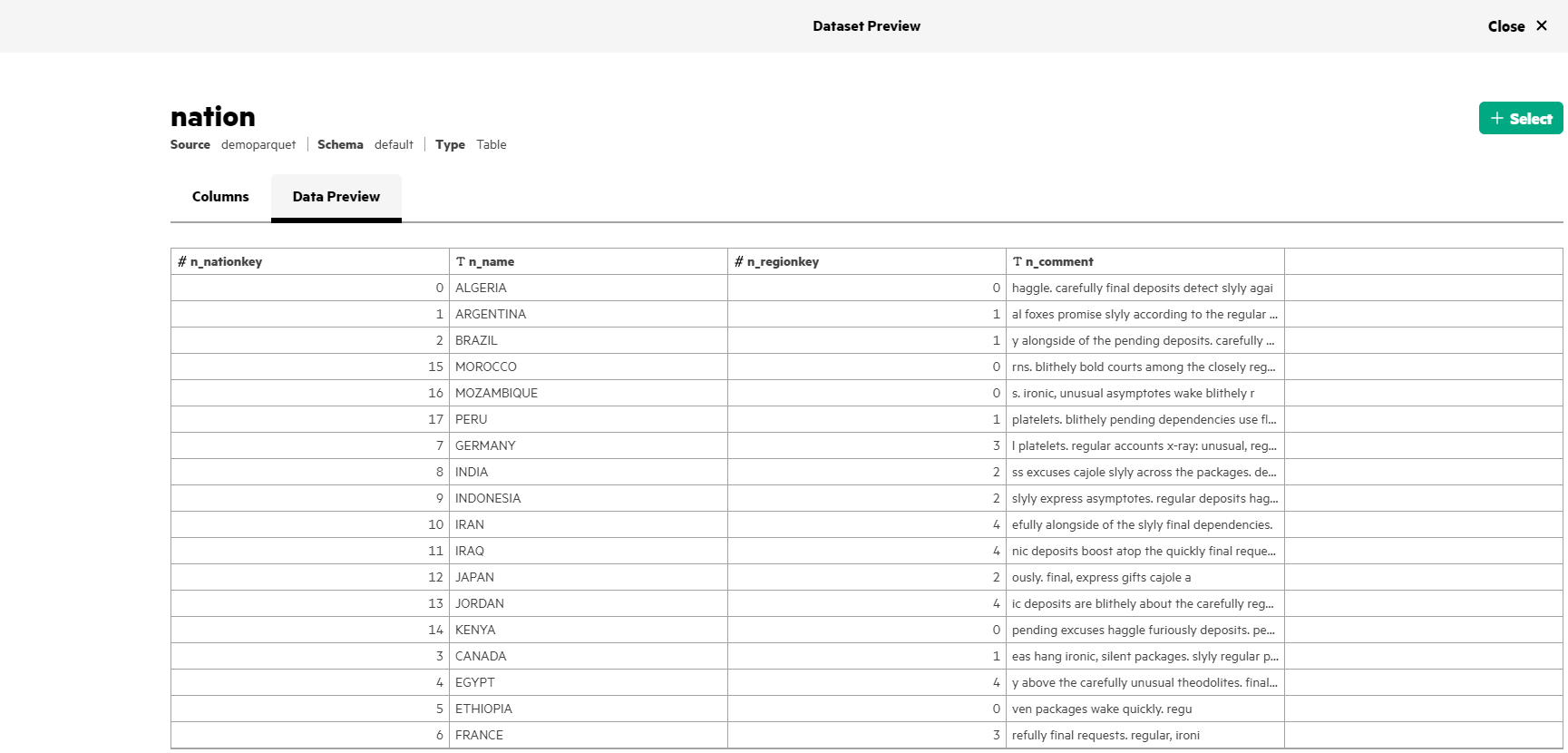
- Click on a table (nation) and then click the Data Preview tab to view the
Parquet data.