Resource Configuration and Management
Describes resource configuration and management for Ray.
Resource Configuration
In HPE Ezmeral Unified Analytics Software, a Ray cluster is deployed using KubeRay Operator.
Currently, the Ray cluster consists of a single head node and a single operator node. Auto-scaling is enabled by default for worker nodes, the Ray cluster automatically scales up and down based on resource demand.
> kubectl -n kuberay get pod
NAME READY STATUS RESTARTS AGE
kuberay-operator-6c75647d8b-7mpqp 1/1 Running 0 22h
ray-cluster-kuberay-head-gw8lc 2/2 Running 0 22hWhen a submitted job demands more resources than the cluster current resources, then the auto scaler will create two more pods.
Auto-scaling is enabled by default configuration so that the Ray cluster creates two more worker pods when needed. If a pod stays idle for 60 seconds, then the auto scaler destroys it.
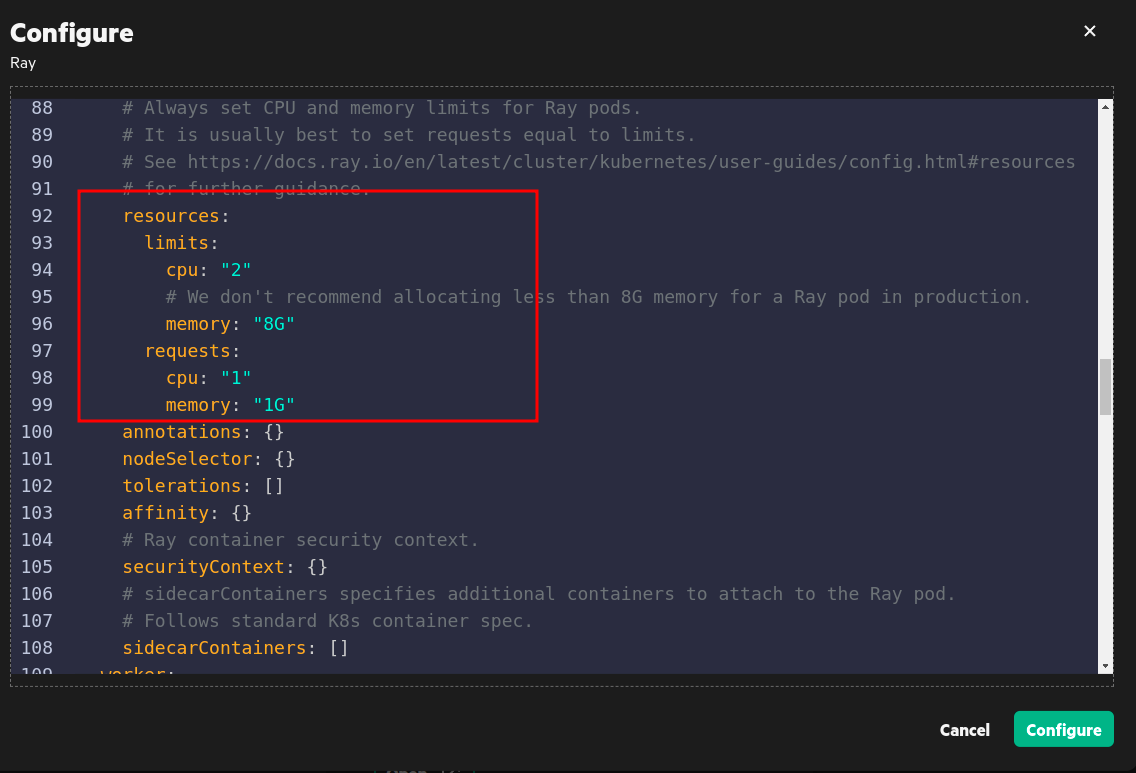
Upper resource limits for pods type are as follows:
- Head pod: 2 CPU and 8 GB memory.
- Worker pod: 3 CPU and 8 GB memory.
Resource Management
- Memory Aware Scheduling
-
By default, Ray does not consider the potential memory usage of a task or an actor when scheduling as it cannot estimate beforehand how much memory is required by the task or actor. However, if you know how much memory a task or an actor might require, you can specify it in the resource requirements of
ray.remotedecorator to enable memory-aware scheduling.For example:# reserve 500MiB of available memory to place this task @ray.remote(memory=500 * 1024 * 1024) def some_function(x): pass# reserve 2.5GiB of available memory to place this actor @ray.remote(memory=2500 * 1024 * 1024) class SomeActor(object): def __init__(self, a, b): pass - Scheduling Strategies
-
There are two scheduling strategies in Ray:
- Default
-
Ray uses
DEFAULTas the default strategy. Currently, Ray assigns tasks or actors on nodes until the resource utilization is beyond a certain threshold and spreads them afterward.For example:@ray.remote def func(): return 1 - Spread
-
Ray uses
SPREADstrategy to spread tasks or actors among available nodes.For example:@ray.remote(scheduling_strategy="SPREAD") def spread_func(): return 2
To learn more see Scheduling Strategies.
Configuring Resources in the UI
- Sign in to HPE Ezmeral Unified Analytics Software as an Administrator.
- Click the Tools & Frameworks icon on the left navigation bar.
- Navigate to the Ray tile under the Data Science tab.
- On the Ray tile, click the three-dots button.
- Select Configure to open the editor.
- In the editor, modify the
resourcessection to adjust resources.