GPU Resource Management
Describes the GPU idle reclaim policy used for GPU resource management.
GPU resource management enables you to optimize the analytical workloads by distributing the GPU resources to various workloads so that each workload receives the necessary computing power.
HPE Ezmeral Unified Analytics Software implements the GPU idle reclaim feature to maximize GPU utilization by dynamically allocating and deallocating resources to different frameworks and workloads as needed. This prevents overallocation and underutilization of the GPU resources and increases efficiency.
GPU resource management uses a priority policy to ensure that critical workloads get the resources they need. The priority policy also allows lower-priority workloads to utilize the GPU when it is available.
When a workload or framework is finished using its GPU resources, HPE Ezmeral Unified Analytics Software initiates GPU resource reclamation. This involves deallocating the resources and making them available for other workloads.
Custom Scheduler
HPE Ezmeral Unified Analytics Software runs its own scheduler which functions independently and is not connected to the default Kubernetes scheduler.
Note that the default Kubernetes scheduler is still available alongside this custom scheduler. The custom scheduler is an enhanced version of the default Kubernetes scheduler that includes the GPU idle reclaim plugins and the preemption tolerance.
hpe-scheduler-plugins namespace. This namespace consists of a controller
and a scheduler module. The scheduler is responsible for scheduling and reclaiming. 
There are two pods in the scheduler namespace. They are
scheduler-plugins-controller-dc8fbd68-2plns and
scheduler-plugins-scheduler-5c9c5579cb-xz48q. To view details of the GPU
reclamation and pod preemption, see the logs for the
scheduler-plugins-scheduler-5c9c5579cb-xz48q pod.
kubectl logs -f scheduler-plugins-scheduler-5c9c5579cb-xz48q -n hpe-scheduler-plugins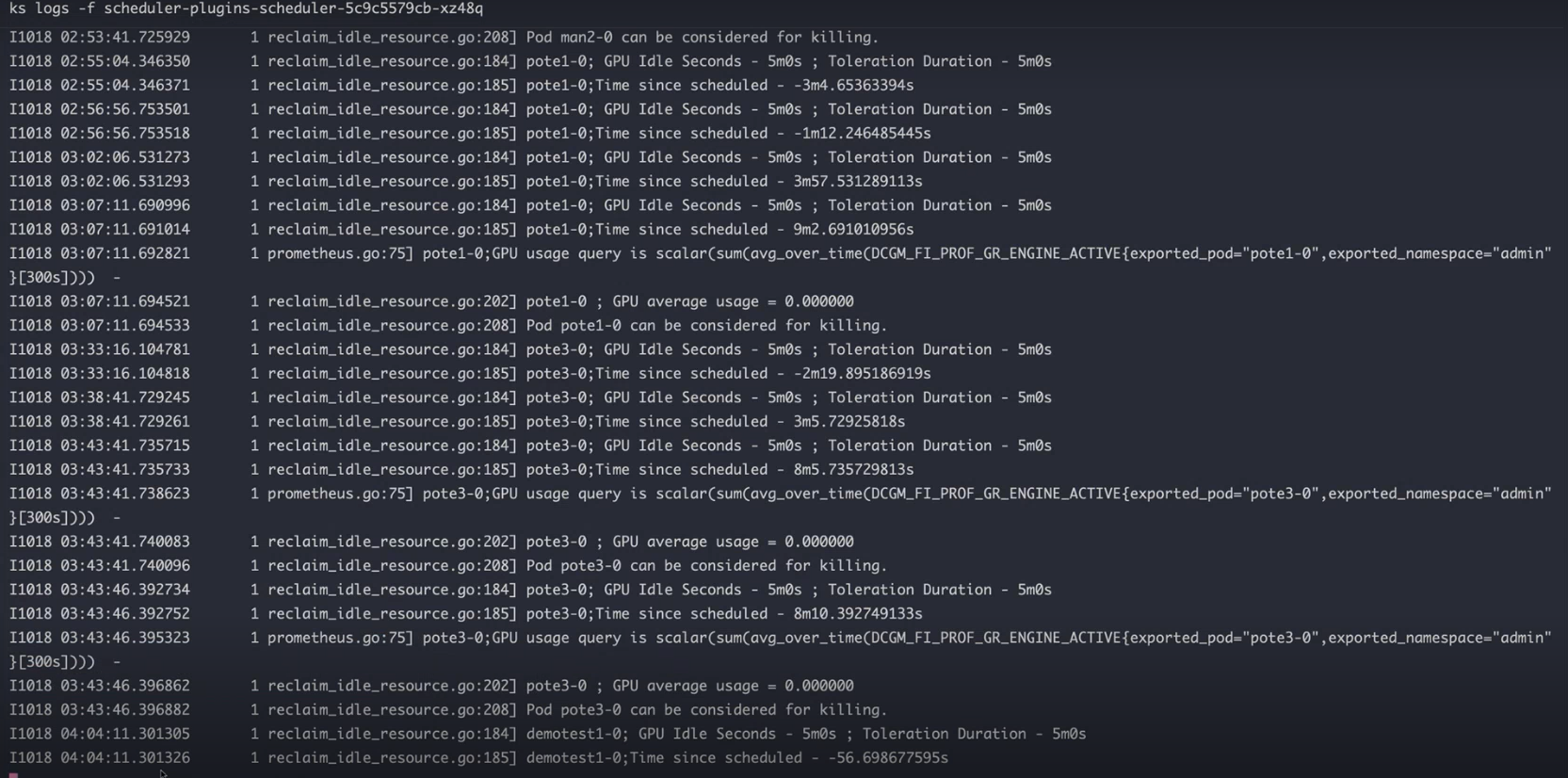
Custom Scheduler Configurations
- Kubeflow
- Spark
- Livy
- Ray
- HPE MLDE
schedulerName: scheduler-plugins-schedulerpriorityClass: <app_name>-<component_name>-gpu- For example,
- For Kubeflow notebooks:
kubeflow-notebook-gpu - For Spark:
spark-gpu(Note: There is no component name for Spark)
- For Kubeflow notebooks:
- For example,
Only pods with their spec.schedulerName set to
scheduler-plugins-scheduler are considered for reclaiming.
Do not modify these configurations for the GPU reclamation. If your GPU pod spec is not set
to scheduler-plugins-scheduler, the default Kubernetes scheduler will
operate instead of the custom scheduler.
GPU Configurations
In HPE Ezmeral Unified Analytics Software, you can configure the priority level and idle time threshold from the GPU Control Panel screen. However, you cannot configure the toleration seconds and GPU usage threshold for workloads.
To learn more about the GPU control panel, see Configuring GPU Idle Reclaim.
- Priority class and priority level
-
HPE Ezmeral Unified Analytics Software attaches priority classes as pod specs to the deployed pods to prioritize pods. The priority class has a number called priority level that determines the importance of a pod.
The custom scheduler determines the priority based on this priority level. The default priority level for all pods is 8000.
You can set the priority level from 8000 to 10000 where 8000 is the lowest priority level and 10000 is the highest priority level. You can update the priority level for your applications and workloads from the GPU Control Panel screen.
- Idle time threshold
-
You can also set the idle time threshold for a GPU from the GPU Control Panel screen. The idle time threshold is the maximum amount of time the GPU can remain idle without running any workloads. If a GPU remains idle for a duration exceeding this threshold, the GPU on those workloads can be reclaimed to make the GPU available for other workloads.
- Toleration seconds
-
Toleration seconds is the minimum number of seconds the pod or workload needs to run before it can be preempted. The default toleration seconds is set to 300 seconds.
- GPU usage threshold
-
The GPU usage threshold is the level of GPU utilization. The default usage threshold is set to 0.0. If any pod has a GPU usage of greater than 0 in the last 300 seconds, it cannot be preempted. For any pods to be preempted, the usage must be 0.0.