GPU Support
Provides information about support for NVIDIA GPU, MIG partitioning, preparing hosts for GPU-enabled environment, adding hosts and enabling GPU in HPE Ezmeral Unified Analytics Software.
GPUs provide essential computational power and parallel processing capabilities to accelerate the training and inference processes of deep learning models, reading and processing data frames, processing SQL queries within Spark, and running experiments using Jupyter notebooks integrated with GPUs.
The hundreds or thousands of smaller cores working in parallel enable GPUs to process massive amounts of data in a short period of time.
HPE Ezmeral Unified Analytics Software supports homogenous configuration deployment where the GPU is split into N equal parts with the same amount of memory and CUDA cores. All GPU models on the same Kubernetes cluster must operate in the same configuration mode. HPE Ezmeral Unified Analytics Software does not support any mixed configuration across multiple GPU models.
Supported GPU Models
To see the GPU models supported by HPE Ezmeral Unified Analytics Software, see GPU Models .
MIG Partitioning
HPE Ezmeral Unified Analytics Software supports single-access multi-instance GPU. You can use MIG GPU when there are multiple applications that require GPU acceleration. By using MIG, you can achieve higher resource utilization and cost efficiency.
In HPE Ezmeral Unified Analytics Software, GPU partitions are presented as whole devices by using the MIG mechanism. When an application requests one GPU, the application receives a partition. Only one GPU device is visible to the application. To learn more, see CUDA visible devices.
During the installation of HPE Ezmeral Unified Analytics Software, you must specify GPU partition size (Whole, Large, Medium, and Small) and request the number of GPU instances required for the workload.
| Unified Analytics vGPU Size | No. of Unified Analytics vGPUs per physical GPU | MIG Profile - A100-40GB | MIG Profile - A100-80GB | Description |
|---|---|---|---|---|
| Whole | 1–100% | No MIG - entire physical GPU | No MIG - entire physical GPU |
A100 GPU models are not split into any partitions. You will get the entire physical GPU. In this configuration, applications can use only one virtual GPU at a time. |
| Large | 2 – 42% each | 3g.20gb | 3g.40gb |
A100 GPU models are split into two equal partitions. In this configuration, 16% of the GPU will remain idle. |
| Medium | 3 – 28% each | 2g.10gb | 2g.20gb |
A100 GPU models are split into three equal partitions. In this configuration, 16% of the GPU will remain idle. |
| Small | 7 – 14% each | 1g.5gb | 1g.10gb |
A100 GPU models are split into seven equal partitions. In this configuration, 2% of the GPU will remain idle. |
| Unified Analytics vGPU Size | No. of Unified Analytics vGPUs per physical GPU | MIG Profile - A30-24GB | Description |
|---|---|---|---|
| Whole | 1–100% | No MIG - entire physical GPU |
A30 GPU models are not split into any partitions. You will get the entire physical GPU. In this configuration, applications can use only one virtual GPU at a time. |
| Large | 2 – 50% each | all-2g.12gb |
A30 GPU models are split into two equal partitions. This configuration will utilize 100% of the GPU. |
| Small | 4 – 25% each | all-1g.6gb |
A30 GPU models are split into four equal partitions. This configuration will utilize 100% of the GPU. |
| Unified Analytics vGPU Size | No. of Unified Analytics vGPUs per physical GPU | MIG Profile - H100-NVL | Description |
|---|---|---|---|
| Whole | 1–100% | No MIG - entire physical GPU |
H100 GPU models are not split into any partitions. You will get the entire physical GPU. In this configuration, applications can use only one virtual GPU at a time. |
| Large | 2 – 45% each | 3g-47gb |
H100 GPU models are split into two equal partitions. In this configuration, 10% of the GPU will remain idle. |
| Medium | 3 – 24% each | 2g.24gb |
H100 GPU models are split into three equal partitions. In this configuration, 28% of the GPU will remain idle. |
| Small | 7 – 12% each | 1g.12gb |
H100 GPU models are split into seven equal partitions. In this configuration, 16% of the GPU will remain idle. |
gpunodeconfig CR.| Unified Analytics vGPU Size | No. of Unified Analytics vGPUs per physical GPU | MIG Profile - H100-PCI | Description |
|---|---|---|---|
| Whole | 1–100% | No MIG - entire physical GPU |
H100 GPU models are not split into any partitions. You will get the entire physical GPU. In this configuration, applications can use only one virtual GPU at a time. |
| Large | 2 – 40% each | 3g-40gb |
H100 GPU models are split into two equal partitions. In this configuration, 20% of the GPU will remain idle. |
| Medium | 3 – 26% each | 2g.20gb |
H100 GPU models are split into three equal partitions. In this configuration, 22% of the GPU will remain idle. |
| Small | 7 – 12% each | 1g.10gb |
H100 GPU models are split into seven equal partitions. In this configuration, 16% of the GPU will remain idle. |
To learn about MIG profile names, see MIG Device Names.
Preparing the GPU Environment
HPE Ezmeral Unified Analytics Software supports GPUs on Kubernetes nodes. The underlying hosts must be running an operating system and version that is supported on the corresponding version of HPE Ezmeral Unified Analytics Software.
HPE Ezmeral Unified Analytics Software supports user-provided deployment.
Preparing hosts to use GPU in the user-provided host model:
- The host can be bare metal or VM with GPU pass-through, or an AWS EC2 instance.
- Install the latest version of the supported operating system. To learn about the
supported operating system versions for GPU in HPE Ezmeral Unified Analytics Software,
see Operating System.NOTEDo not use operating systems with pre-installed NVIDIA drivers. HPE Ezmeral Unified Analytics Software does not support operating systems with pre-installed NVIDIA drivers. The GPU operator automatically installs NVIDIA drivers when the host is added to HPE Ezmeral Unified Analytics Software.
- Disable SELinux on the host before adding the host to HPE Ezmeral Unified Analytics Software. This is the NVIDIA limitation, see GPU Operator with RHEL8/SELinux.NOTEAfter successfully adding the host to HPE Ezmeral Unified Analytics Software cluster and the successfull NVIDIA driver install through the GPU operator, you can enable SELinux on that host and set it to enforcing mode.
To learn more about user-provided hosts, see Installing on User-Provided Hosts (Connected and Air-gapped Environments).
| Environments | Description |
|---|---|
| vSphere VM |
Configure the VMs in the GPU pass-through setup by following the steps in VMware setting up GPU pass-through documentation. Add hosts to the HPE Ezmeral Unified Analytics Software. |
| AWS |
Use the AWS account with access to provision GPU-based instances (p4d.24xlarge, and p4de.24xlarge EC2 instances). Deploy the A100 EC2 instance (P4d instance) with the AMI image in the supported operating system. Add hosts to the HPE Ezmeral Unified Analytics Software. |
Adding Hosts and Enabling GPU Environment
After you have prepared hosts to work in the GPU-enabled environment, you must add them to the HPE Ezmeral Unified Analytics Software during the installation or during cluster expansion. After adding the host, the GPU is enabled automatically.
- Adding Hosts and Selecting GPU Environment During Installation
-
To add hosts and select the GPU environment in the cluster during installation, follow these steps :
- Perform the installation instructions provided in the installation documentation for your deployment target until you reach the Installation Details step in the installation wizard. See Installation.
- In the Installation Details step, to enable the GPU, check Use
GPU.
- vGPU: Specify the vGPU instances for your
cluster.
The number of vGPUs allocated depends on the GPU configuration partition size, the number of added GPU worker hosts, and the number of GPU cards per host. The number of allocated vGPUs may be less than the number of requested vGPUs.
For example: If one A100 GPU host is added with two GPU cards with the following configurations:- vGPU request: 10 vGPUs
- vGPU configuration: large
Then the number of allocated vGPUs is as follows:- vGPUs allocated: 2 x 2 large per GPU card = 4
- GPU Configuration: Specify the GPU partition size.
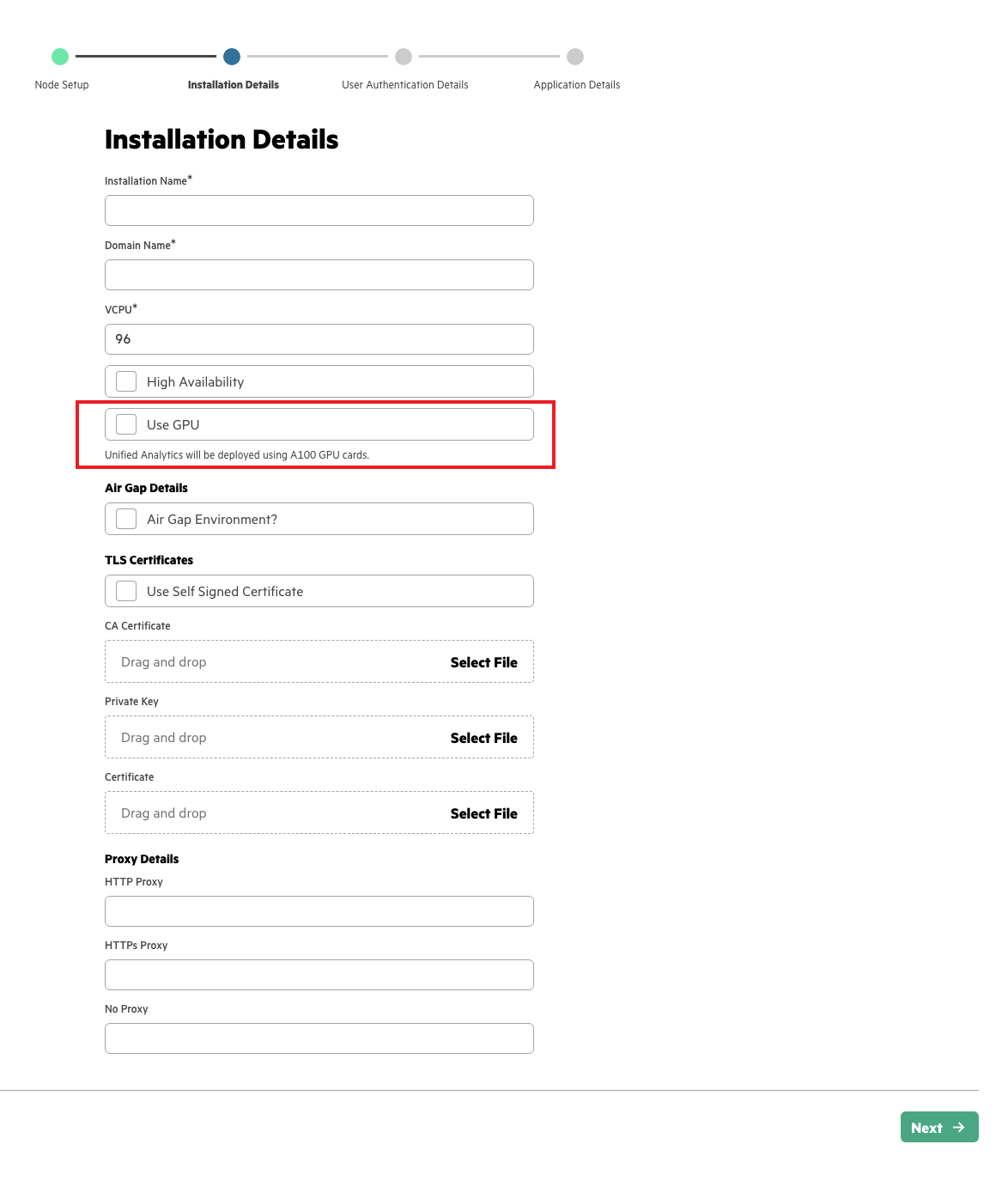
As each node is added to the HPE Ezmeral Unified Analytics Software inventory node pool, HPE Ezmeral Unified Analytics Software configures the MIG profile if it detects MIG-capable devices (e.g., A100).
- vGPU: Specify the vGPU instances for your
cluster.
-
To specify the details for other boxes or options in the Installation Details step and to complete the cluster installation, refer to the installation documentation for your deployment target. See Installation.
- Adding Hosts and Selecting GPU Environment During Cluster Expansion
-
To add hosts and select the GPU environment in the cluster during cluster expansion, follow these steps:
- Perform the steps to expand the cluster until you reach the Expand Cluster screen. See Expanding the Cluster.
- To enable the GPU, in the Expand Cluster screen, check
Use GPU. NOTEIf you enabled the Use GPU option during the cluster installation, then that means GPU is already enabled and you cannot disable the Use GPU option while expanding the cluster.
- vGPU: Specify the additional vGPU instances for your
cluster.NOTEThe number of additional vGPUs allocated depends on the GPU configuration partition size, the number of added GPU worker hosts, and the number of GPU cards per host. The number of allocated vGPUs may be less than the number of requested vGPUs.
- GPU Configuration: Specify the GPU partition size.
NOTEIf you selected the partition size during the cluster installation, you can not update the partition size while expanding the cluster.
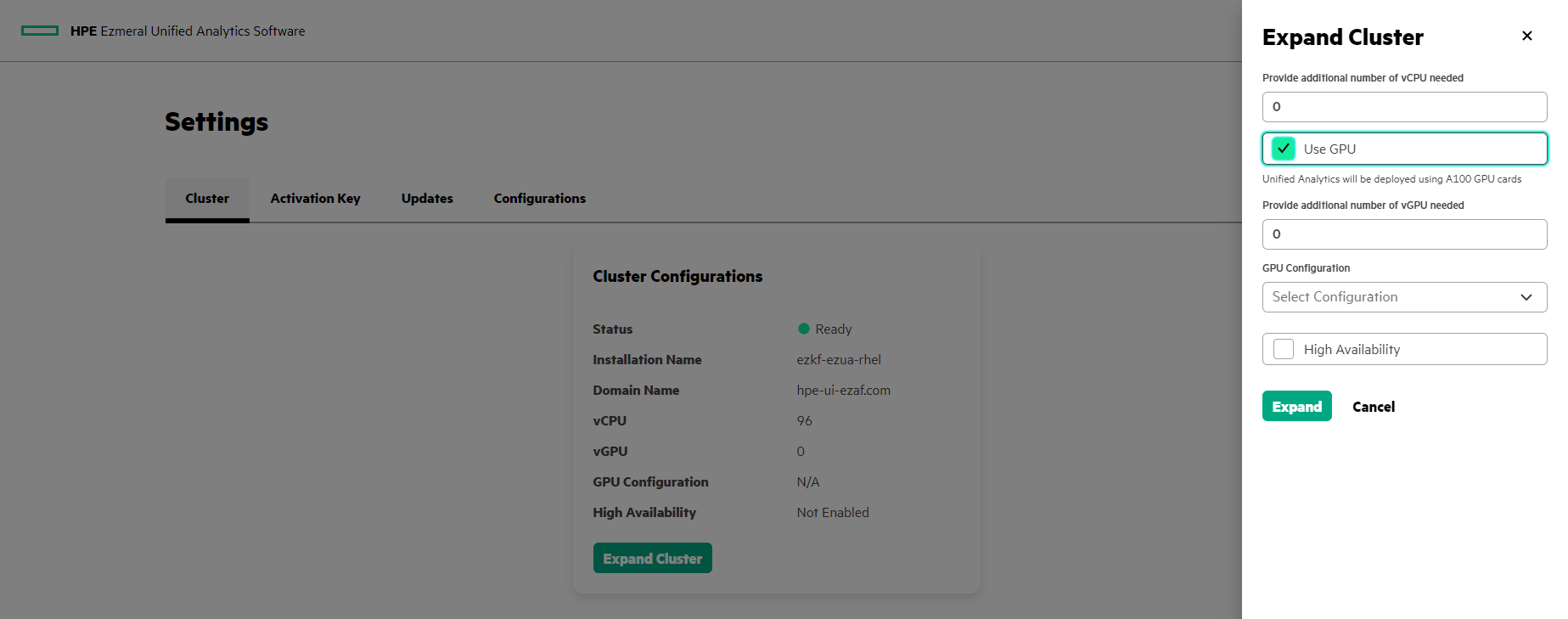
- vGPU: Specify the additional vGPU instances for your
cluster.
-
To specify the details for other boxes or options in the Expand Cluster screen and to complete the cluster expansion, see Expanding the Cluster.
Viewing GPU Model Information
lspci | grep -i nvidiaTo learn more about supported operating systems for GPUs in HPE Ezmeral Unified Analytics Software, see Operating System.
Updating GPU Partition Size Post Installation
To update the GPU partition size, modify the gpunodeconfig CR as
follows:
- Verify that the GPU workloads are not running in the cluster. To verify, SSH into the
GPU node, run the following
command:
Then, look for any processes consuming the GPU. If no processes are shown, the GPU is not in use. Ensure this is consistent across all GPU nodes in the cluster.chroot /run/nvidia/driver/ nvidia-smi - To fetch the resource name, SSH into the workload control plane node and run the
following
command:
gpunodeconfig=$(kubectl get gpunodeconfig -n hpecp-gpunodeconfig -o jsonpath='{.items[].metadata.name}') - To update the partition size, update the
enabledfield with the partition size of your choice.For example, to update the partition size to
large, run:kubectl patch gpunodeconfig $gpunodeconfig -n hpecp-gpunodeconfig --type merge -p '{"spec":{"enabled":"large"}}' - To verify that the new partition size is applied in your cluster, run the following
command inside the driver daemon pod in the
hpecp-gpu-operatornamespace:nvidia-smi
Integrating GPU with Tools and Frameworks
nvidia.com/gpu resource
specifier. nvidia.com/mig-Xg.YYgb.- Kubeflow Kale or KFP. See Enabling Kale Extension in Kubeflow Notebook.
- Kubeflow KServe. See Enabling GPU Support on Kubeflow Kserve Model Serving.
- Kubeflow Notebooks. See Creating GPU-Enabled Notebook Servers.
- Ray. See GPU Support for Ray.
- Spark. See Enabling GPU Support for Spark.