Making Prediction Calls With Deployed Models
This topic describes the requirements and a template for making a prediction call to the deployed model.
Prerequisites
Required access rights: Project Administrator or Project Member
About this task
This task is part of the process to put a model into production. After the model has been developed and registered in the HPE Ezmeral Runtime Enterprise model registry, you deploy the model, which enables prediction calls to be sent to this model.
Procedure
-
Get an auth token for the prediction call.
To make a prediction on the deployed model, a user token is required. The procedure to get the token depends on whether you are using the grapical user interface (GUI) or the command line.
Using the GUI:
-
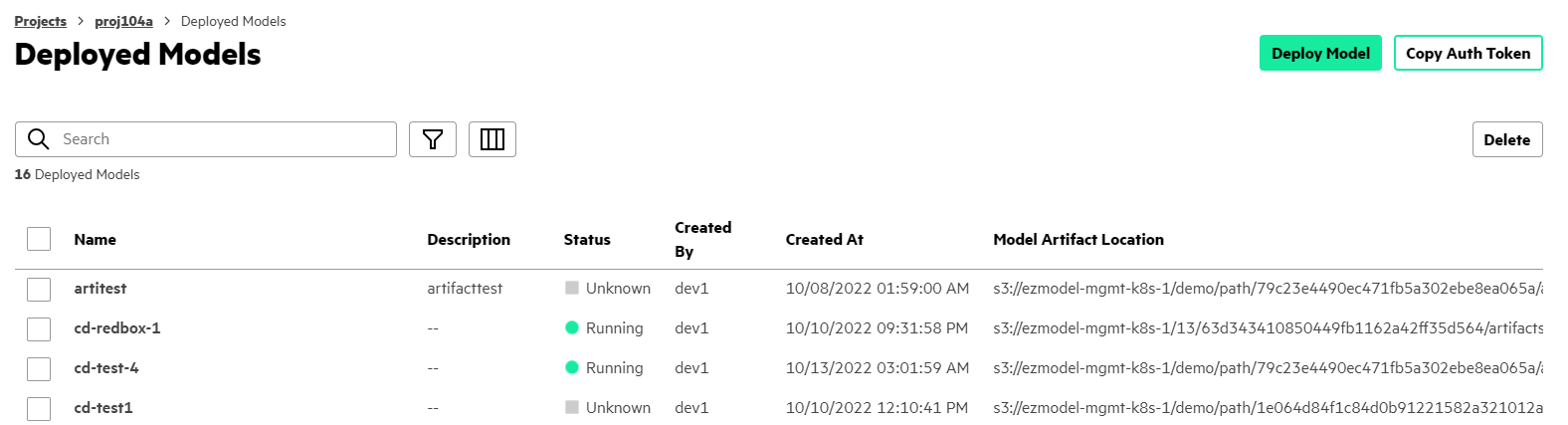
Select View All on the Deployed
Models panel. The Deployed Models
screen opens.
-
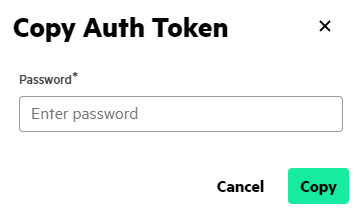
Select Copy Auth Token. The Copy Auth
Token menu appears.
Using the command line:The token expires after 24 hours by default. After the token expires, existing processes continue to run, but subsequent requests are returned with a 403 error, and you must obtain a new token.
-
Select View All on the Deployed
Models panel. The Deployed Models
screen opens.
- Retrieve the model endpoint by selecting for a running model.
-
Make a prediction call.
Using the model endpoint, an auth token, and data, make a prediction call on the deployed model.
For example:curl --cookie "authservice_session=xxxxxxxxxxxxxxxxxxxxxxxxxxx" \ -X POST -H 'Content-Type: application/json' -d '{"data": {"ndarray":["This film has great actors"]}}' \ http://localhost:8003/seldon/seldon/movie/api/v1.0/predictionsA general template for a prediction call usingcurlis as follows:
Thecurl --cookie "authservice_session=<auth-token>" -X POST \ -H 'Content-Type: application/json' -d <data> <access-point><data>in this call is a JSON representation of an array or a dataframe. For example, the following represents an array:
When the data contains a names field, a dataframe is assumed. The type of predict call (dataframe or array) depends on the input requirement for the model artifact.-d '{"data": {"ndarray":[[39, 7, 1, 1, 1, 1, 4, 1, 2174, 0, 40, 9]]}}'For more information about the Seldon prediction call, see External Prediction API in the official Seldon Core documentation (link opens an external site in a new browser tab or window).