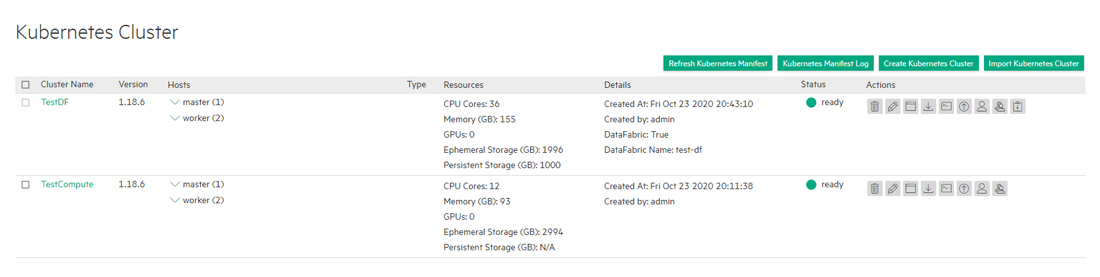
Expanding a Data Fabric Cluster
This procedure describes how to expand an HPE Ezmeral Data Fabric on Kubernetes cluster deployed on HPE Ezmeral Runtime Enterprise.
You can only expand HPE Ezmeral Data Fabric on Kubernetes clusters that were created with HPE Ezmeral Runtime Enterprise version 5.2 or later.
When you create or expand an HPE Ezmeral Data Fabric on Kubernetes cluster, you
cannot reuse existing Kubernetes hosts that were added to HPE Ezmeral Runtime Enterprise without specifying the
Datafabric tag. However, you can decommission the hosts from
the HPE Ezmeral Runtime Enterprise as described in Decommissioning/Deleting a Kubernetes Host, then add the
Datafabric tag to the hosts, and then select the hosts when
creating or expanding the Data Fabric cluster.
You cannot modify the cluster HA status during expansion.
- Changing the value of the
DisableHAkey is ignored. - You cannot add pods during cluster expansion if doing so would change the cluster HA status.
To expand a Data Fabric cluster:
- Add the Data Fabric nodes that will be used to expand the Data Fabric cluster, as described in Kubernetes Data Fabric Node Installation Overview.
-
Click the Edit icon (pencil) for the Data Fabric cluster.
The Step 1: Hosts Configuration screen appears. The Datafabric check box is grayed out and cannot be edited.
-
In the Masters row of the Hosts table, hover the mouse over a node in the Available column.
A right arrow appears.
-
Click the arrow.
The selected node moves from the Available Hosts column to the Selected Hosts column. To deselect a node, you may hover the mouse over a selected node and then click the left arrow to move it back to the Available Hosts column. You must select an odd number of Master nodes in order to have a quorum (e.g. 3, 5, 7, etc.). Hewlett Packard Enterprise recommends selecting three or more Master nodes to provide High Availability protection for the Data Fabric cluster. Master nodes cannot use the
Datafabrictag.By default, a taint is placed on the Master nodes that prevents them from being able to run pods. You must untaint these nodes if you want them, to be available to run pods, as described here (link opens an external web site in a new browser tab/window).
- Repeat Steps 4 and 5 for the Worker nodes. You may add or remove as many Worker
nodes as needed to this cluster. NOTE
You may select Master and Worker nodes with or without the
Datafabric=yestag.- Nodes tagged
Datafabric=yesare used for Data Fabric storage. - Nodes that are not tagged
Datafabric=yesare included in the Data Fabric cluster, but are used for compute functions only.
NOTEYou can search for nodes by clicking the Search icon (magnifying glass) above any of the four cells in the Hosts table and then typing any portion of the hostname. The list of nodes automatically refreshes as you type. - Nodes tagged
- Proceed with Steps 2 and onward of Editing an Existing Kubernetes Cluster.NOTE
You cannot change add-ons when expanding a Data Fabric cluster.
HPE Ezmeral Runtime Enterprise validates the make-up of the intended cluster
expansion in a manner similar to that when the Data Fabric cluster was created. If validation succeeds,
then the existing Data Fabric CR is retrieved and
updated to reflect the expansion. A Data Fabric
cluster expansion supports an increased failurecount for CLDB and/or
Zookeeper pod sets provided that the value of the disableha key in the
Data Fabric CR does not change.
HPE Ezmeral Runtime Enterprise automatically determines whether to add CLDB and Zookeeper nodes and MFS groups. New MFS pods, if any, will be added in new MFS groups that are appended to the list of existing MFS groups already present in the Data Fabric CR.
The web interface expansion process completes quickly, and the Kubernetes Clusters screen may show the expanded Data Fabric cluster in the Ready state, but the newly-added pods may still be coming up.
If desired, you can manually fine-tune the Data Fabric cluster by modifying the cluster Custom Resource file (CR), as described in Manually Creating/Editing a Data Fabric cluster.