Manually Creating/Editing a Data Fabric cluster
A Custom Resource file (CR) is the blueprint for creating a Data Fabric cluster. Data Fabric cluster creation therefore begins with either creating a new CR or editing an existing CR for the cluster. The CR specifies settings for the core components (such as CLDB, ZooKeeper, MCS, or Objectstore gateway) and the shared services (such as Hive Metastore) to be installed in the cluster.
If you are editing a Data Fabric cluster that was created in HPE Ezmeral Runtime Enterprise as described in Creating a New Data Fabric Cluster, then a new CR is automatically created for that cluster. This CR is the blueprint for how the Data Fabric cluster should be created by the DataPlatform operator. However, you can customize the CR to match your unique workflow usage using the information presented in this article.
The DataPlatform operator reads this blueprint and creates the cluster. This operator consists of:
- A Custom Resource Definition (CRD) that contains the syntax and required properties for creating the Custom Resource.
- A Controller pod that uses the Custom Resource to build the Data Fabric cluster.
The DataPlatform operator can deploy one HPE Ezmeral Data Fabric on Kubernetes cluster per HPE Ezmeral Runtime Enterprise deployment. This cluster consists of the core, metrics, logging, object gateway, and shared services. The following illustration shows the default list of Data Fabric cluster components deployed by the DataPlatform operator:
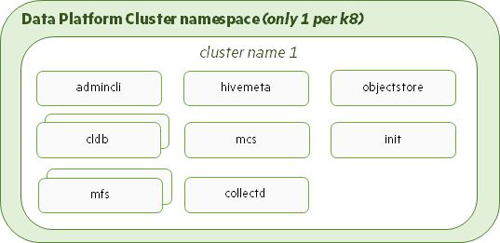
Data Fabric CR Parameters
The Data Fabric CR can contain values for some or all of the following properties:
baseimagetag- string - The tag to use for pulling all images from a common build. Use this tag to avoid specifying an individual tag for each image.imageregistry- string - Image registry location. This should be the full registry tag. See the sample CRs for the default Google cloud registry.- imagepullsecret - string - Name of the secret that contains login information for the image repository.
environmenttype- string - Kubernetes environment in which to deploy the storage cluster on. This must be set tovanilla.-
simpledeploymentdisks- array - List of disks to use in case of a simple deployment where all nodes have the same number of existing disks. For a more complex deployment, specify the disk information in thediskinfoobject ofcldbandmfs. The default value is:/dev/sdb /dev/sdc /dev/sdd disableha- boolean - Whether (true) or not (false; default) to disable High Availability (HA) enforcement for all pods. Disabling HA turns off HA pod guarantees, such as running only a single instance of CLDB or ZK instead of the minimum three. Enabling enforcement launches enough pods to ensure an HA cluster even if you request lower individual pod counts.dnsdomain- string - Kubernetes cluster DNS domain suffix to use. The default value iscluster.local.loglocation- string - Top-level writable directory where cluster logs are stored on the host machine. An extra level of hierarchy is added underneath this directory to separate information from a different cluster and cluster create times. The default value is/var/log/mapr. Container logs are stored in a subdirectory on the pod.corelocation- string - Optionally specifies the host location where core files for cluster pods are stored. The default value of/var/log/mapr/corescan be changed to any writable location on the host node.podinfolocation-string - Top-level directory where persistent pod information is stored. An extra level of hierarchy is added underneath this directory to separate information from a different cluster. The default value is/var/log/mapr/podinfo.security- object- Settings for installing a secure Data Fabric cluster. See Security Object Settings.debuginfo- object - Settings for debugging the logs. See Debuginfo Object Settings .core- object- Settings for the core Data Fabric cluster pods. See Core Object Settings.monitoring- object - Settings for monitoring services. See Monitoring Object Settings.gateways- object - Settings for gateway service pods. See Gateway Object Settings.coreservices- object - Settings for other Data Fabric services. See Core Services Settings.externaldomain- string - External domain of the host or NAT addresses used for external connections. Default is empty.
Security Object Settings
These are the security settings for all of the pods in the Data Fabric cluster. The security
object in the Data Fabric CR must contain values
for the following properties:
systemusersecret- string - Name of the secret that contains system user information for starting the pods in Kubernetes.disablesecurity- boolean - Whether (true) or not (false; default) security should be disabled.usedare- boolean - Whether (true) or not (false; default) data-at-rest encryption must be enabled on the cluster. This must be set tofalseifdisableSecurityis set tofalse.
DebugInfo Object Settings
Specify cluster-wide debugging settings that apply to all pods. Changing the
debugging level for an individual pod overrides the cluster-wide settings. The
debugging object in the Data Fabric CR must contain values for the following
properties:
loglevel- string - See Bootstrap Log Levels.preservefailedpods- boolean - Whether (true) or not (false; default) pods should not be allowed to restart in the event of a failure. Setting this value to true simplifies pod debugging, but causes the cluster to lose the native Kubernetes resilience that arises from pods restarting themselves when there is a problem.wipelogs- boolean - Whether (true) or not (false; default) to remove log information at the start of a container run. This setting is ignored ifhostidis already present.
Core Object Settings
The core object in the Data Fabric
CR must contain values for the following properties:
init- object - Pod initialization settings for cluster key and certificate generation. The init pod generates initial cluster information including security keys based on the specification in the cluster CR. The cluster will not function if theinitcontainer does not start. Once started, theinitcontainer runs as a job and disappears after its work is finished. See Core Init Object Settings.zookeeper- object - ZooKeeper pod settings. Zookeeper contains critical cluster coordination information used by the MCS,maprcli, and CLDB. ZooKeeper pods run as part of astatefulset. See ZooKeeper Core Object Settings.cldb- object - CLDB pod settings. CLDB contains location information for all data stored in HPE Ezmeral Data Fabric. CLDB pods run as part of a statefulset. See CLDB Core Object Settings.mfs- object - File system pod settings. MFS pods physically store your data and run as part of a statefulset. See MFS Core Object Settings.webserver- object - Data Fabric Control System settings. The web-server containers run as part of a statefulset and host the admin interface. WebServer Core Object Settings.admincli- object - Admin client pod settings for administering the core data platform components. Admin CLI pods run as part of a statefulset. See AdminCLI Core Object Settings. Kubernetes Cluster Administrators log in to the Admin CLI to run various cluster maintenance tasks. See Admin CLI Pod.
Core Init Object Settings
The init object in the core object of the Data Fabric CR must contain values for the following
properties:
image- string - Image to use for theinitpod container. The default value isinit-<mapr-version>:<baseimagetag>.[sizing fields]- strings - See Pod Sizing Fields.loglevel- string - See Bootstrap Log Levels.
ZooKeeper Core Object Settings
The zookeeper object in the core object of the
Data Fabric CR must contain values for the
following properties:
failurecount- integer - Number of failures to tolerate. IfdisableHAis enabled (set totrue), then you can specify a value of0to create a single ZooKeeper instance. Otherwise, create3ZooKeeper instances for a single failure and increment by2for each additional failure to tolerate. For example, the default value of1creates3ZooKeeper instances, a value of2, creates5ZooKeeper instances, and so on.image- string - Image to use for the pod container. The default value iszookeeper-<mapr-version>:<baseimagetag>.[sizing fields]- strings - See Pod Sizing Fields.sshport- integer - Node port to use to handle external SSH requests. The default value is5000.loglevel- string - See Bootstrap Log Levels.
CLDB Core Object Settings
Diskinfo Settings is deprecated from HPE Ezmeral Data Fabric on Kubernetes version 1.5, and user does not need to
specify any details about the disks.
All disks present on the host will be categorized as
hdd/ssd/nvme device and made available in the
cldb/mfs pods under /dev/mapr/edf-disks
path.
MFS Core Object Settings
The mfs object in the core object of the Data Fabric CR must contain values for the following
properties:
image- string - Image to use for the pod container. The default value ismfs-<mapr-version>:<baseimagetag>.sshport- integer - Node port to use to handle external SSH requests. The default value is5001.hostports- object - Externally-available pod ports. The default value for a single file system instance is5660, 5692, 5724, 5756, 8660. See HostPorts CLDB and MFS Group Object Settings.requestcpu- string - CPU amount to reserve for the pod, in the format([1 - 9][0-9]+m). For example:200m.limitcpu- string - Maximum CPU for the pod, in the format([1 - 9][0-9]+m). For example:12000m.requestmemory- string - Amount of memory to reserve for the pod, in the format([1 - 9]+Gi). For example:4Gi.limitmemory- string - Maximum memory amount for the pod, in the format([1 - 9]+Gi). For example:4Gi.requestdisk- string - Amount of ephemeral storage space to reserve for the pod. Default is5Gi.limitdisk- string - Maximum amount of ephemeral storage space to reserve for the pod. Default is20Gi.loglevel- string - See Bootstrap Log Levels.
MFS Group Object Settings
Diskinfo Settings is deprecated from HPE Ezmeral Data Fabric on Kubernetes version 1.5, and user does not need to
specify any details about the disks.
All disks present on the host will be categorized as
hdd/ssd/nvme device and made available the
cldb/mfs pods under /dev/mapr/edf-disks.
HostPorts CLDB and MFS Group Object Settings
The hostports object in the cldb and mfs:groups
object of the Data Fabric CR must contain values
for the following properties:
mfs1port- integer - First file system port. The default value is5660. For each additional instance, the port number is incremented by 1. That is, instance 0 will use5660, instance 1 will use5661, and so on for each additional instance.mfs2port- integer - Second file system port. The default value is5692. For each additional instance, the port number is incremented by 1. That is, instance 0 will use5692, instance 1 will use5693, and so on for each additional instance.mfs3port- integer - Third file system port. The default value is5724. For each additional instance, the port number is incremented by 1. That is, instance 0 will use5724, instance 1 will use5725, and so on for each additional instance.mfs4port- integer - Fourth file system port. The default value is5756. For each additional instance, the port number is incremented by 1. That is, instance 0 will use5756, instance 1 will use5757, and so on for each additional instance.
MFS Group DiskInfo Object Settings
The diskinfo object in the mfs:groups object of the
Data Fabric CR must contain values for the
following properties:
diskcount- integer - Number of disks in this group. The default value is3. Pods for this service are not created on nodes that do not meet this requirement. This is ignored ifsimpledeploymentdisksinformation is specified in the Data Fabric CR.disktype- string - Type of disk in this group (hdd,ssd,nvme). The default value isssd. Pods for this service will not be created on nodes that do not meet this requirement.reducemfsrequirements- boolean - Whether (true) or not (false; default) memory and CPU resources required by MFS should be reduced at the expense of DB performance.storagepoolsize- integer - Number of disks in the storage pool. This is configured during disksetup (link opens in a new browser tab/window). The default value is0, which uses a single storage pool. Any other number is passed to thedisksetuputility as the stripe width. For example, if there are10disks and the storage pool size is2, then5storage pools with2disks each are created, and if the storage pools size is5the2storage pools of5disks each are created.storagepoolsperinstance- integer - Number of storage pools that an instance of the file system will manage. The platform launches multiple instances of the file system based on the specified number of storage pools. The default value is0, which sets the number of storage pools based on internal algorithms. A value greater than32generates an error.
WebServer Core Object Settings
The webserver object in the core object of the
Data Fabric CR must contain values for the
following properties:
count- integer - Number of pod instances. At least one instance of the Data Fabric Control System (MCS) is required.image- string - Image to use for the pod container. The default value iswebserver-<mapr-version>:<baseimagetag>.[sizing fields]- strings - See Pod Sizing Fields.sshport- integer - Node port to use to handle external SSH requests.loglevel- string - See Bootstrap Log Levels.
AdminCLI Core Object Settings
The admincli object in the core object of the
Data Fabric CR must contain values for the
following properties:
count- integer - Number of pod instances. At least one instance of the admin CLI is required.image- string - Image to use for the pod container. The default value isadmincli-<mapr-version>:<baseimagetag>.[sizing fields]- strings - See Pod Sizing Fields.sshport- integer - Node port to use to handle external SSH requests. The default value is5003.loglevel- string - See Bootstrap Log Levels.
Monitoring Object Settings
The monitoring object of the Data Fabric CR must contain values for the following
properties:
monitormetrics-boolean - Whether (true; default) or not (false) to enable monitoring of some cluster metrics using the installed monitoring services such ascollectd, OpenTSDB, or Grafana.collectd- object -Collectd settings. Collectd runs as a deployment and collects various metrics from running pods. See CollectD Monitoring Object Settings.opentsdb- object - OpenTSDB settings. OpenTSDB pods run as part of a statefulset and hold the metrics generated by Collectd. See OpenTSDB Monitoring Object Settings.grafana- object - Grafana settings. Grafana pods run as part of a deployment and provide the interface for the metrics stored in OpenTSD. See Grafana Monitoring Object Settings.
CollectD Monitoring Object Settings
The collectd object in the monitoring object of the
Data Fabric CR must contain values for the
following properties:
disablecollectd- boolean - Whether (true) or not (false; default) to disable collectd.image- string - The image to use for the pod container. The default value iscollectd-<version>:<baseimagetag>.[sizing fields]- strings - See Pod Sizing Fields.loglevel- string - See Bootstrap Log Levels.
OpenTSDB Monitoring Object Settings
The opentsdb object in the monitoring object of the
Data Fabric CR must contain values for the
following properties:
count- integer - Number of pod instances.image- string - Image to use for the pod container. The default value isopentsdb-<version>:<baseimagetag>.[sizing fields]- strings - See Pod Sizing Fields.loglevel- string - See Bootstrap Log Levels.
Grafana Monitoring Object Settings
The grafana object in the monitoring object of the
Data Fabric CR must contain values for the
following properties:
count- integer - Number of pod instances.image- string - Image to use for the pod container. The default value isgrafana-<version>:<baseimagetag>.[sizing fields]- strings - See Pod Sizing Fields.loglevel- string - See Bootstrap Log Levels.
Gateway Object Settings
The gateways object of the Data Fabric CR must contain values for the following
property:
objectstore- object - Settings for the Data Fabric Object Store with S3-Compatible API. The Objectstore runs as a statefulset and allows S3/Minio API requests to data platform data. See Object Store Gateway Object Settings.
Object Store Gateway Object Settings
The objectstore object in the gateways object of
the Data Fabric CR must contain values for the
following properties:
count- integer - Number of pod instances.image- string - Image to use for the pod container. The default value isobjectstore-<version>:<baseimagetag>.[sizing fields]- strings - See Pod Sizing Fields.sshport- integer - Node port on the node to use to handle external SSH requests.hostports- object - Externally-usable pod port.loglevel- string - See Bootstrap Log Levels.
Core Services Settings
Core services are additional pods that run in the Data Fabric cluster namespace, which means that core service pods are a single high availability cluster per Data Fabric cluster. Hive Metastore runs as a deployment and is currently the only non-gateway or monitoring cluster service that runs in the Data Fabric cluster namespace. This configuration allows Hive Metastore to be shared across tenants. If needed, Hive Metastore can also be run as a tenant service. The Hive Metastore object contains values for the following Hive Metastore properties:
count- integer - Number of pod instances.image- string - Image to use for the pod container. The default value ishivemeta-<version>:<baseimagetag>.useexternaldb- boolean - Whether (true) or not (false; default) Hive Metastore should use an external DB instead of the embedded Derby DB.externaldbserver- string - DB server address to use for Hive Metastore. This value is ignored ifuseexternaldbis set tofalse.[sizing fields]- strings - See Pod Sizing Fields.sshport- integer - Node port to use to handle external SSH requests.loglevel- string - See Bootstrap Log Levels.
Custom Configuration File Settings
In the clusterCustomizationFiles object in the cluster CR
- The custom configuration files specified using ConfigMaps in the CR are deployed
in the
hpe-templates-datanamespace. Pods use the settings in the ConfigMaps when launching a service. - The custom configuration files specified using Secrets in the CR are deployed in
the
hpe-securenamespace. Pods use the settings in the Secrets when launching a service.
The clusterCustomizationFiles object in the cluster CR contains
values for the following properties:
podSecurityPolicy- string - Name of the pod security policy that should be used by the Data Fabric cluster. This should be in thehpe-securenamespace.networkPolicy- string - Name of the network policy that should be used by the Data Fabric cluster. This should be in thehpe-securenamespace.- sslSecret - string - Name of the secret containing SSL certificates that should
be used by the Data Fabric cluster. This
should be in the
hpe-securenamespace. sshSecret- string - Name of the secret containing SSH keys that should be used by the Data Fabric cluster. This should be in thehpe-securenamespace.zkConfig- string - Name of the ConfigMap containing ZooKeeper settings that should be used by the Data Fabric cluster. The default value iszookeeper-cm.cldbConfig- string - Name of the ConfigMap containing CLDB settings that should be used by the Data Fabric cluster. The default value iscldb-cm.mfsConfig- string - Name of the ConfigMap containing MapR file system settings that should be used by the Data Fabric cluster. The default value ismfs-cm.webserverConfig- string - Name of the ConfigMap containing Data Fabric Control System (MCS) settings that should be used by the Data Fabric cluster. The default value iswebserver-cm.collectdConfig- string - Nme of the ConfigMap containing collectD settings that should be used by the Data Fabric cluster. The default value iscollectd-cm.opentsdbConfig- string - Name of the ConfigMap containing OpenTSDB settings that should be used by the Data Fabric cluster. The default value isopentsdb-cm.grafanaConfig- string - Name of the ConfigMap containing Grafana settings that should be used by the Data Fabric cluster. The default value isgrafana-cm.objectstoreConfig- string - Name of the ConfigMap containing MapR Object Store settings that should be used by the Data Fabric cluster. The default value isobjectstore-cm.hiveMetastoreConfig- string - Name of the ConfigMap containing Hive Metastore settings that should be used by the Data Fabric cluster and tenant. The default value ishivemetastore-cm.adminCLIConfig- string - Name of the ConfigMap containing Admin CLI settings that should be used by the Data Fabric cluster. The default value isadmincli-cm.tenantCLIConfig- string - Name of the ConfigMap containing Tenant Terminal settings that should be used by the tenant. The default value istenantcli-cm.
Deploying HPE Ezmeral Data Fabric on Kubernetes
To create the HPE Ezmeral Data Fabric on Kubernetes environment:
- Create or edit the custom resource (CR) YAML file for the Data Fabric cluster. The settings in the CR are described previously in this topic.
-
Execute the following command to use the CR to create the Data Fabric cluster:
kubectl apply -f <path-to-data-platform-cluster-custom-resource-file>Containers are created on the pods for running the Data Fabric cluster services when the Data Fabric CR is deployed.
-
Verify whether or not the Data Fabric cluster has been created by executing the following command. The cluster namespace is the cluster name that was specified in the CR:
kubectl get pods -n <data-fabric-cluster-namespace>