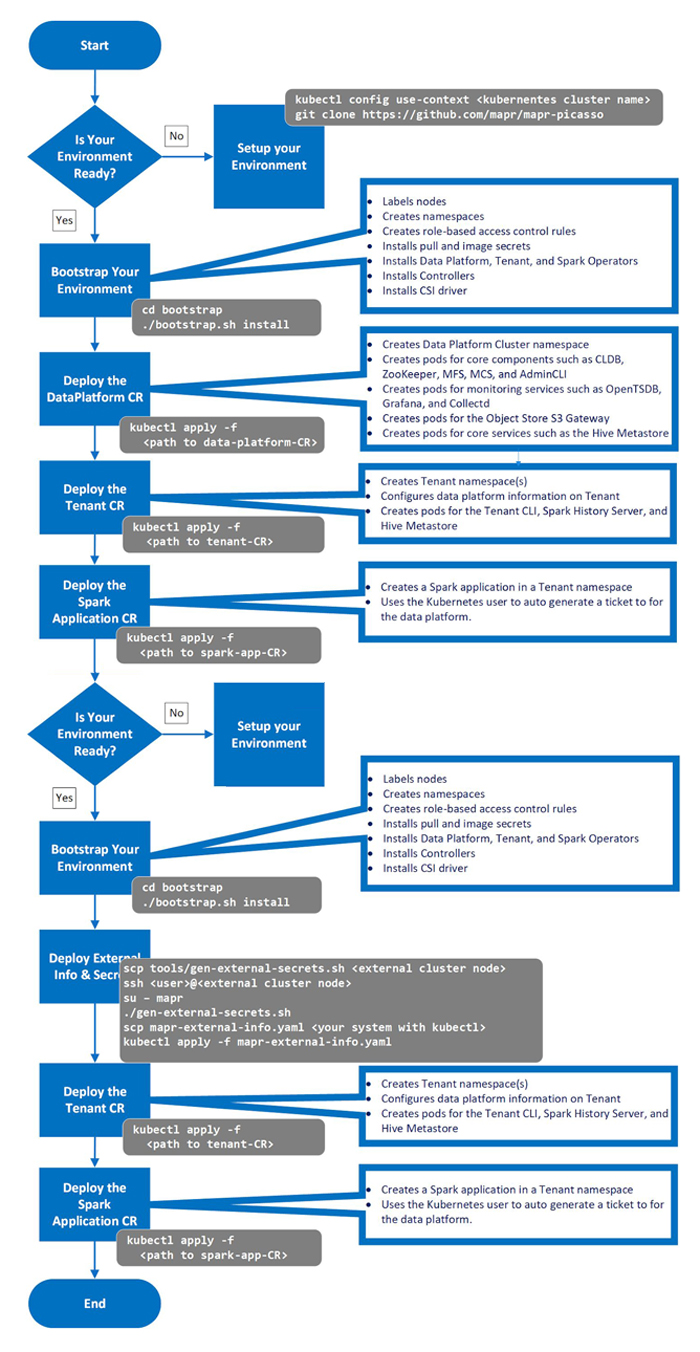
Manual Deployment Workflow
HPE Ezmeral Runtime Enterprise versions 5.2 and later automate many of the processes described in this article. See:
This information is presented for educational, maintenance, and debugging by users with advanced knowledge of HPE Ezmeral Data Fabric.
NOTE
In this article, the term tenant refers to Data Fabric tenants (formerly '"MapR tenants") and not to
Kubernetes tenants unless explicitly noted otherwise on a case-by-case basis. The general manual workflow to deploy HPE Ezmeral Data Fabric on Kubernetes is the following:
- Configure
kubectlto point to your Kubernetes environment, as described here (link open an external website in a new browser tab/window). - Run the bootstrap utility, as described in Manually Bootstrapping the Environment.
- Manage the nodes and disks used by HPE Ezmeral Data Fabric clusters and tenants, as described in Manually Managing Nodes and Disks.
- Either:
- No existing HPE Ezmeral Data Fabric on Kubernetes cluster: Install a Data Fabric CR to create a Data Fabric cluster, as described in either Creating a New Data Fabric Cluster or Manually Creating/Editing a Data Fabric cluster.
- With an existing HPE Ezmeral Data Fabric on Kubernetes cluster: See CR Parameters.
- Do one of the following:
- If you are creating the tenant in a Kubernetes environment outside the storage cluster environment, then deploy external storage cluster host information and user, server, and client secrets, as described in Setting Up External Storage Cluster Secrets.
- If the tenant is in the same environment as the storage cluster, procede to the next step.
- Install one or more Tenant CRs to create new tenants, as described in Tenant CR Parameters.
- Optionally, install a Spark CR for a Spark job.
The following diagram depicts this process: