Rent Forecasting Model (Ray Serve)
Provides an end-to-end example for creating a notebook server and building a machine learning model to forecast rental prices, evaluate its accuracy, and deploy it for real-time predictions using Ray Serve in HPE Ezmeral Unified Analytics Software.
Prerequisites
- Be sure to review the following documentation before using the notebook files on GitHub.
- Sign in to HPE Ezmeral Unified Analytics Software.
- Verify that the installed Ray client and server versions match. To verify,
complete the following steps in the terminal:
- To switch to Ray's environment,
run:
source /opt/conda/etc/profile.d/conda.sh && conda activate ray - To verify that the Ray client and server versions match, run
:
ray --version
- To switch to Ray's environment,
run:
About this task
- Generate a synthetic dataset of rental properties with attributes such as square footage, number of bedrooms, number of bathrooms, and furnishing status to train the prediction model.
- Format and input the generated data to the model for training.
- Use the Random Forest model to predict the monthly rental prices.
- Evaluate the predictive performance of the model using the Mean Absolute Error (MAE) on the testing data set.
- Visualize the performance of the model using
matplotlibwhich shows the graph for Actual vs Predicted Rent Prices. - After completing the model training process, save the model and deploy the
model as a web service using Ray Serve. This allows you to manage request
handling and scalability efficiently.
- First, initialize the Ray environment and start Ray Serve with the appropriate configuration settings to ensure smooth deployment and operation of service.
- Once Ray Serve is up and running, it manages the incoming
HTTPrequests and directs them to the deployed model for prediction.
- View the deployed application in the Ray Dashboard under the Serve tab.
- Wait for the deployed application to be in a Running state.
- Send
HTTPrequests to the deployed model to obtain prediction results. These requests contain the input data that you want the model to make predictions on, and the response contains the corresponding predictions generated by the model. - After obtaining the prediction results, terminate deployment.
Procedure
-
Create a notebook server using the
jupyter-data-scienceimage with at least 3 CPUs and 4 Gi of memory in Kubeflow. See Creating and Managing Notebook Servers.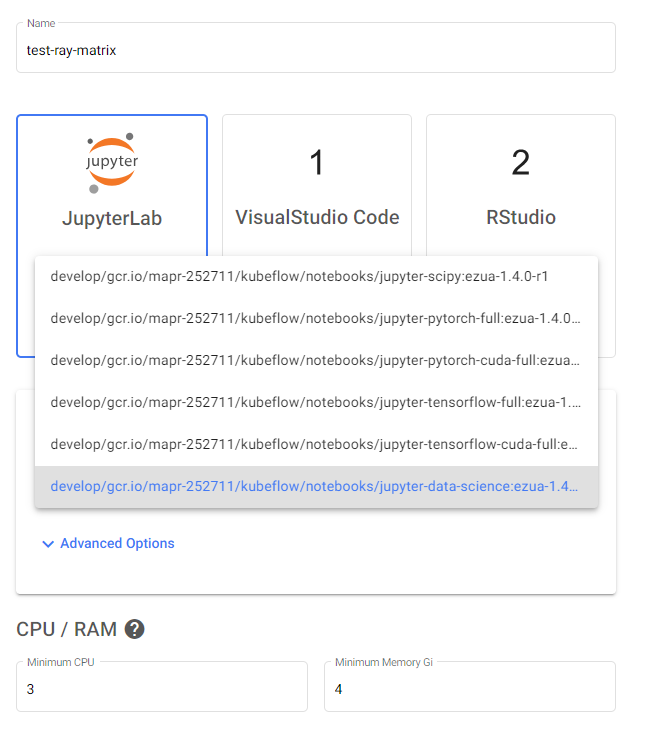
- In your notebook environment, activate the Ray-specific Python kernel.
-
To ensure optimal performance, use dedicated directories containing only the
essential files needed for that job submission as a working directory.
NOTE
If you do not see the
Ray-Servefolder in the<username>directory, copy the folder from theshared/ezua-tutorials/current-release/Data-Science/Raydirectory into the<username>directory. Theshareddirectory is accessible to all users. Editing or running examples from theshareddirectory is not advised. The<username>directory is specific to you and cannot be accessed by other users.If theRay-Servefolder is not available in theshared/ezua-tutorials/current-release/Data-Science/Raydirectory, perform:- Go to GitHub repository for tutorials.
- Clone the repository.
- Navigate to
ezua-tutorials/Data-Science/Ray. - Navigate back to the
<username>directory. - Copy the
Ray-Servefolder from theezua-tutorials/Data-Science/Raydirectory into the<username>directory.
-
Open the
ray-serve-executor.ipynbfile in the<username>/Ray-Servedirectory. -
Select the first cell of the
ray-serve-executor.ipynbnotebook and click Run the selected cells and advance (play icon). Continue until you run the following block of code which generates therent_predictor_app_config.yamlconfiguration file.
-
Run the following block of code to generate URI. Currently,
serve deploydoes not directly support the--working-diroption. You must specify the generated URI from the output of this block of code in therent_predictor_app_config.yamlfile.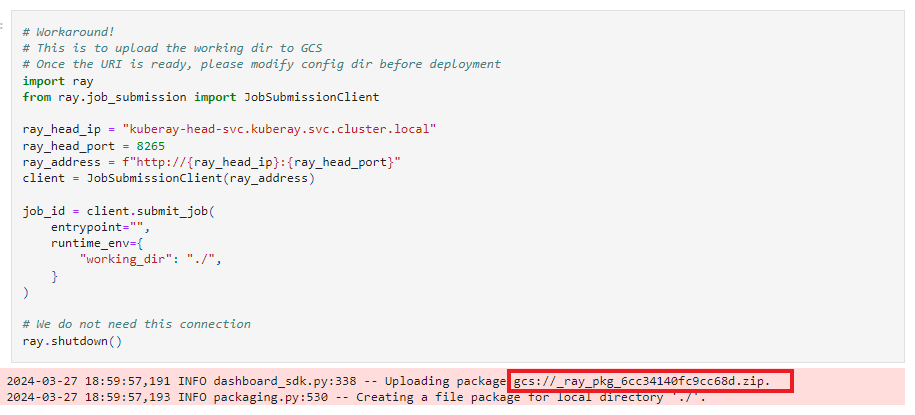
-
Open the
rent_predictor_app_config.yamlfile. -
Specify the generated URI in the
rent_predictor_app_config.yamlfile as follows:runtime_env: working_dir: "<generated-URI>" #example: gcs://_ray_pkg_fef565b457f470d9.zip -
Navigate back to the
ray-serve-executor.ipynbnotebook file and continue to run cells until you reach the following block of code.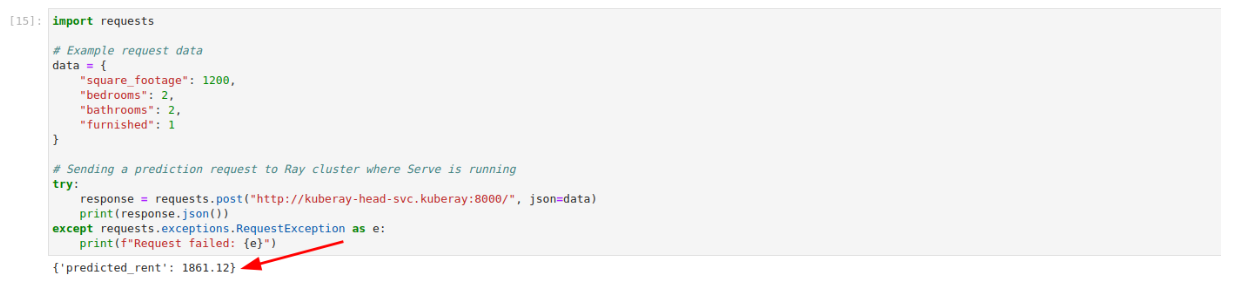
-
View the deployed application in Ray Dashboard under the
Serve tab.
-
Navigate back to the
ray-serve-executor.ipynbnotebook file. -
Run the following block of code:
You will obtain the prediction result as Predicted rent: 1861.12. - After obtaining the prediction results, terminate deployment.
Results
This tutorial shows that by using Ray Serve and Ray cluster deployed in HPE Ezmeral Unified Analytics Software, you can efficiently deploy, manage, and scale your machine learning model as a web service to obtain prediction results.