MLflow Bike Sharing Use Case
Provides an end-to-end workflow in HPE Ezmeral Unified Analytics Software for an MLflow prediction model to determine bike rentals per hour based on weather and time.
IMPORTANT
Be sure to review the following documentation before using the notebook
files on GitHub.Run the Bike Sharing Use Case
- In the left navigation pane, click Notebooks.
- Connect to your notebook server instance. For this example, select
hpedemo-user01-notebook.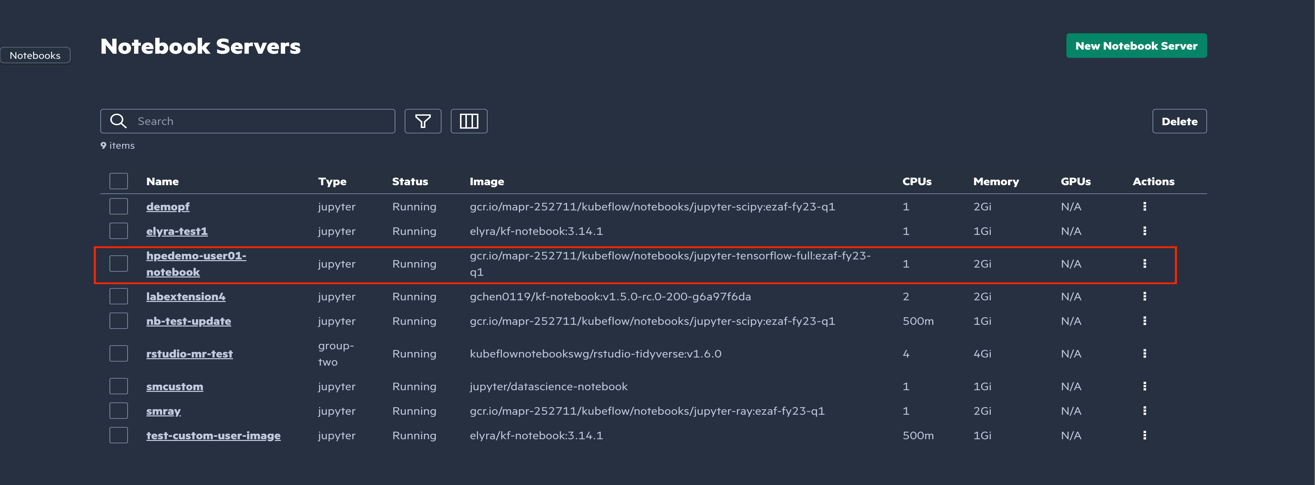
- Copy the
MLFlowfolder from theshareddirectory into the<username>directory.NOTEIf theMLflowfolder is not available in theshareddirectory, perform: -
Open
bike-sharing-mlflow.ipynband import mlflow and install libraries. After you finish, restart the kernel and run all the cells, including those you previously ran.NOTEIf you are using the local s3-proxy, do not set the following environment variables for MLflow. However, if you are trying to connect from outside the cluster, you must set the following environment variables.os.environ["AWS_ACCESS_KEY_ID"] = os.environ['MLFLOW_TRACKING_TOKEN'] os.environ["AWS_SECRET_ACCESS_KEY"] = "s3" os.environ["AWS_ENDPOINT_URL"] = 'http://local-s3-service.ezdata-system.svc.cluster.local:30000' os.environ["MLFLOW_S3_ENDPOINT_URL"] = os.environ["AWS_ENDPOINT_URL"] os.environ["MLFLOW_S3_IGNORE_TLS"] = "true" os.environ["MLFLOW_TRACKING_INSECURE_TLS"] = "true" - Run the notebook cells.
Running the notebook returns the details of the best model:

Track Experiment, Runs, and Register a Model in MLflow
- Navigate to the MLflow UI. You should see the bike-sharing-exp experiment.
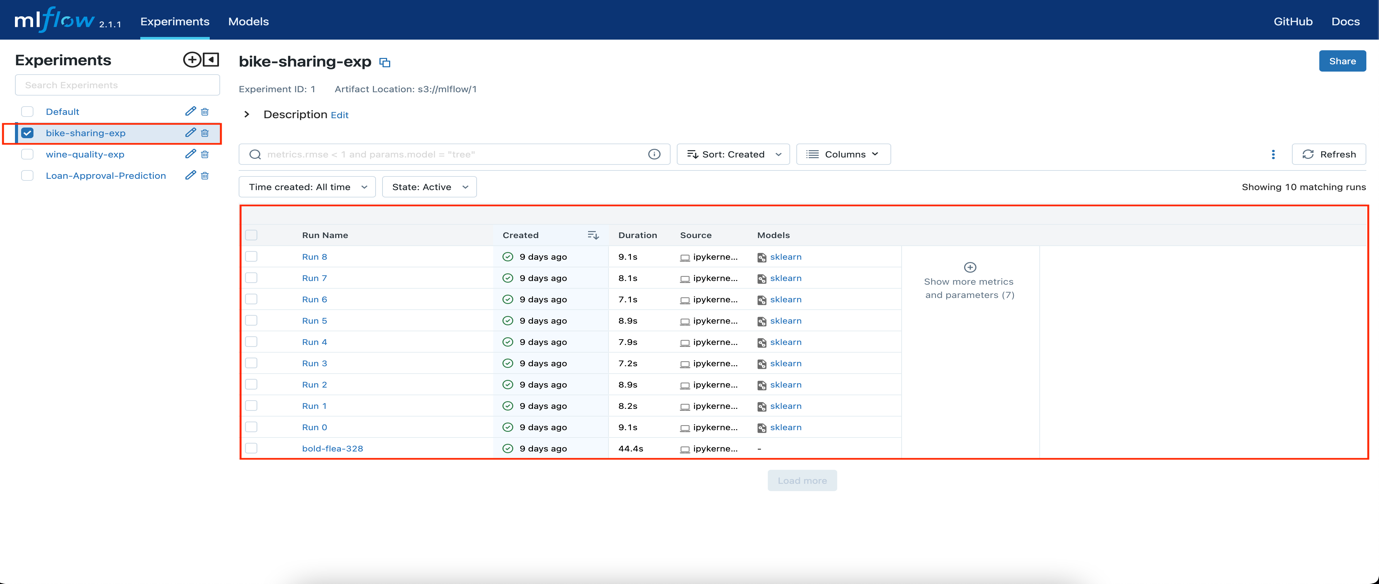
- Select the best model and then select Register Model. In this
example, the best model is run 2.
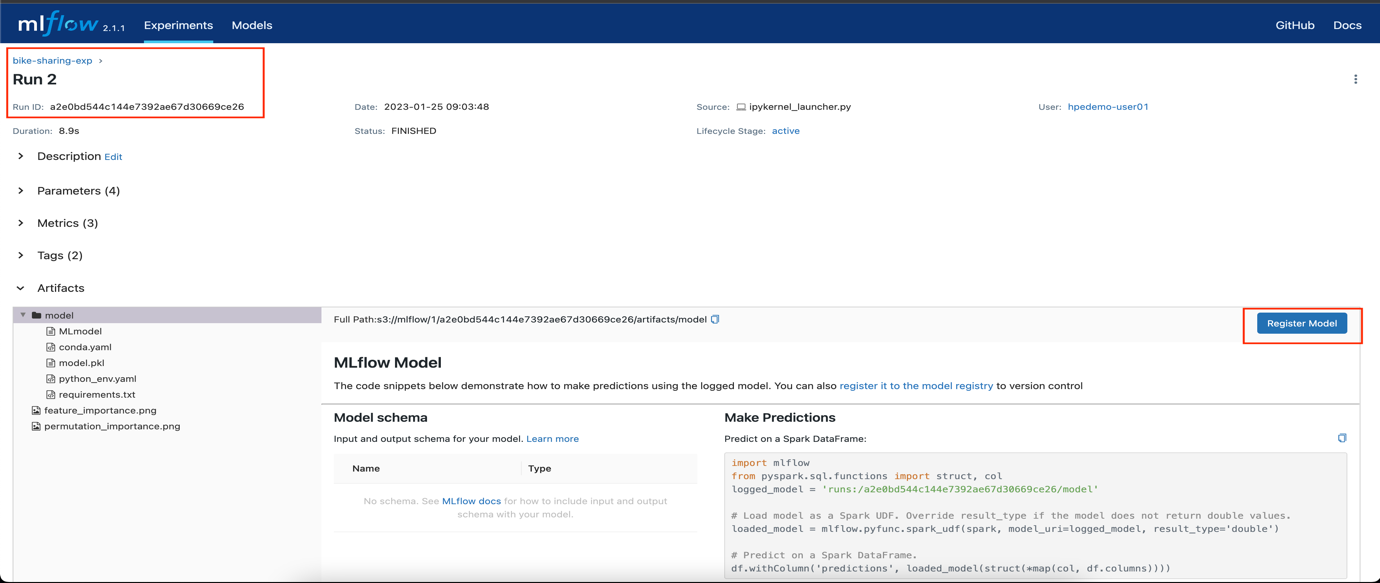
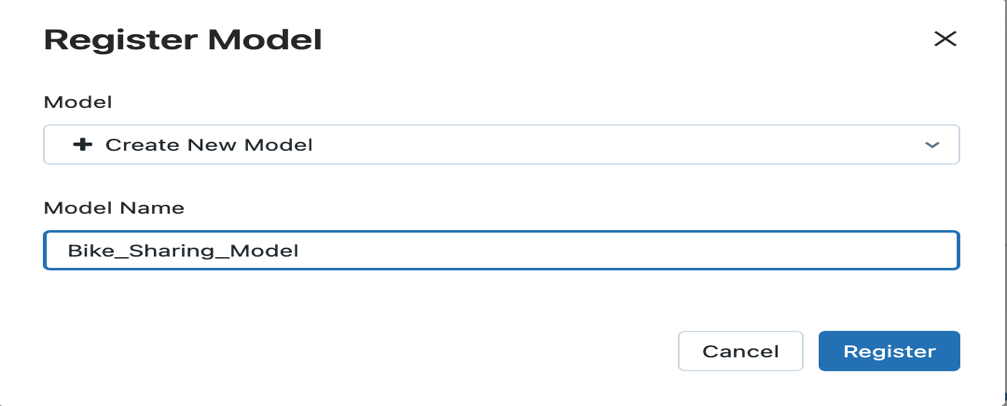
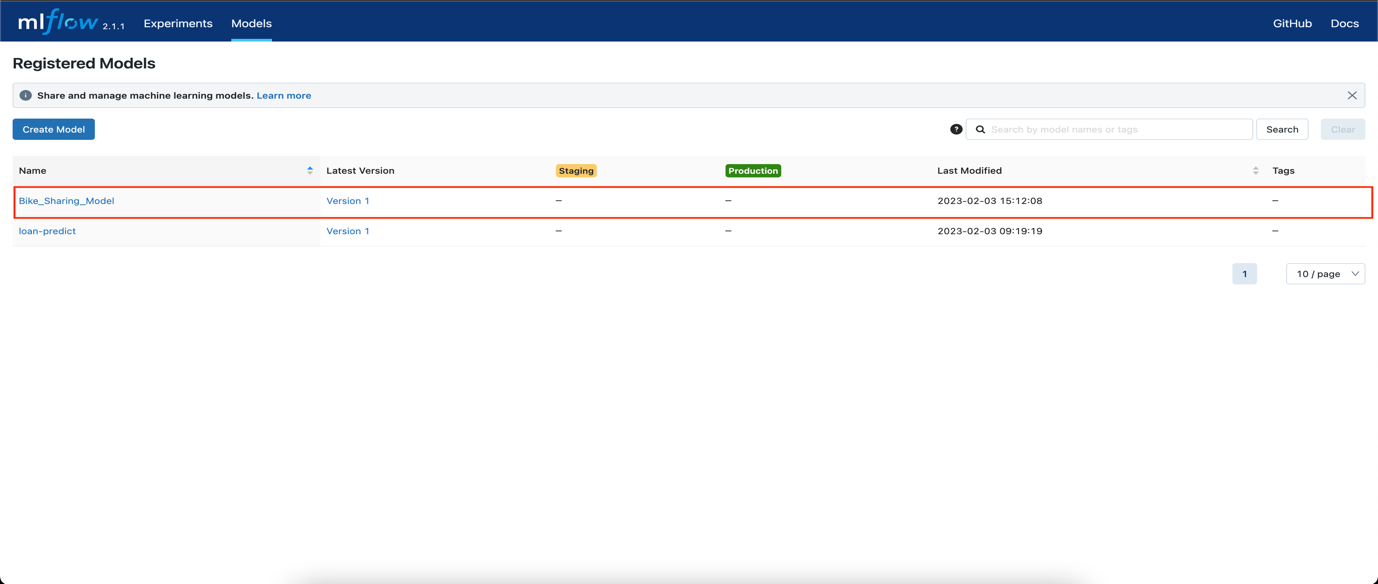
- In the Register Model window, enter Bike_Sharing_Model and click
Register.
- Click on the Models menu to view the registered models.
Use the Model for Prediction
- Navigate to the notebook server and open
bike-sharing-prediction.ipynb. - Run the first cell and wait until the
bike-sharing-predictorpod goes into the running state.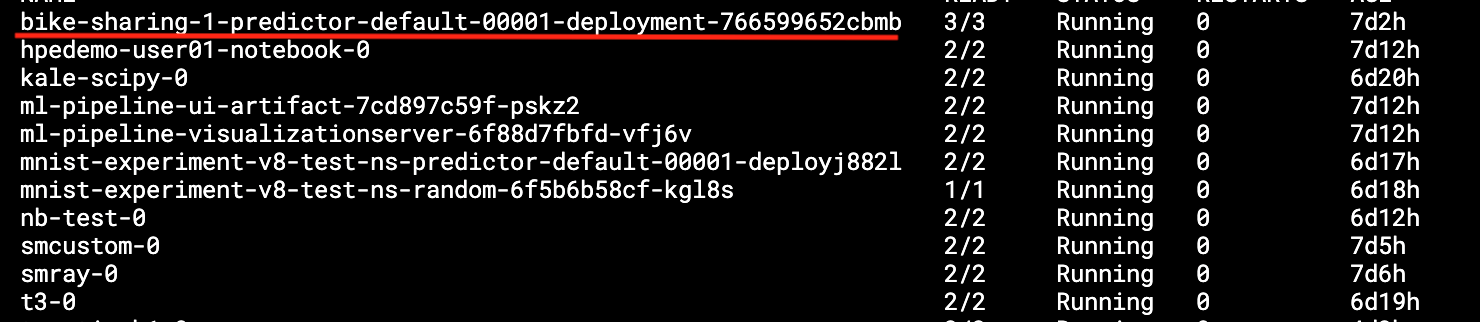
- Run the second cell to deploy machine learning model using KServe inference service.
Note: Update DOMAIN_NAME to your domain for external access and save changes.The system prints the following predictions for the input:
Rented Bikes Per Hours: Input Data: {'season': 1, 'year': 2, 'month': 1, 'hour_of_day': 0, 'is_holiday': 0, 'weekday': 6, 'is_workingday': 0, 'weather_situation': 1, 'temperature': 0.24, 'feels_like_temperature': 0.2879, 'humidity': 0.81, 'windspeed': 0.0} Bike Per Hour: 108.90178471846806 Input Data: {'season': 1, 'year': 5, 'month': 1, 'hour_of_day': 0, 'is_holiday': 0, 'weekday': 6, 'is_workingday': 1, 'weather_situation': 1, 'temperature': 0.24, 'feels_like_temperature': 0.2879, 'humidity': 0.81, 'windspeed': 0.0} Bike Per Hour: 84.96339548602367