Running Ray GPU Example
Describes how to run the Ray GPU example in HPE Ezmeral Unified Analytics Software.
Prerequisites
- Be sure to review the following documentation before using the notebook files on GitHub.
- Sign in to HPE Ezmeral Unified Analytics Software.
- Verify that the installed Ray client and server versions match. To verify,
complete the following steps in the terminal:
- To switch to Ray's environment,
run:
source /opt/conda/etc/profile.d/conda.sh && conda activate ray - To verify that the Ray client and server versions match, run
:
ray --version
- To switch to Ray's environment,
run:
- Verify that the GPU support is enabled in your Ray cluster. See Enabling GPU Support During HPE Ezmeral Unified Analytics Software Installation or Enabling GPU Support and Configuring Resources After HPE Ezmeral Unified Analytics Software Installation.
About this task
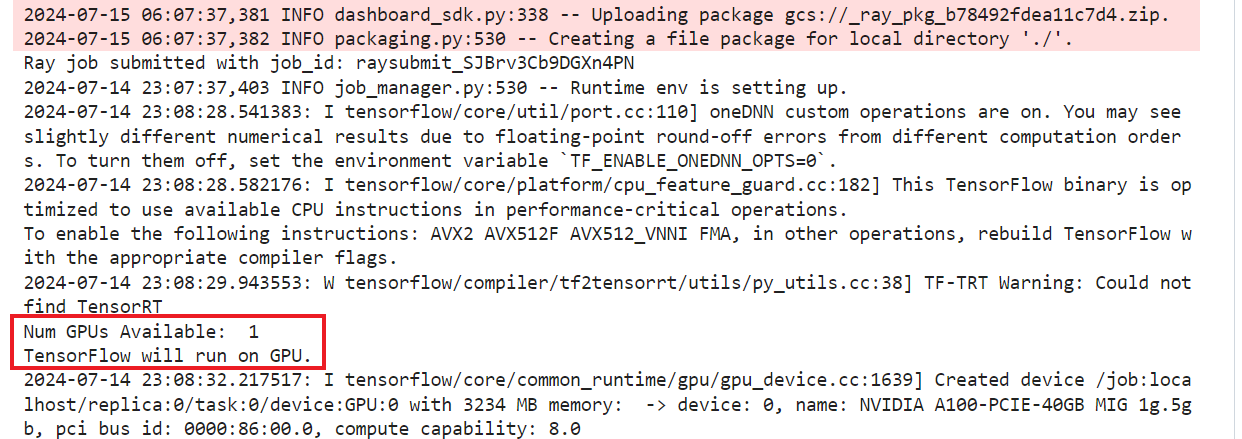
In this tutorial, you will run the sample Ray GPU example and analyze logs to ensure that Unified Analytics is running the GPU-accelerated jobs.
You will complete the following steps:
Procedure
-
Create a notebook server using the
jupyter-tensorflow-cuda-fullimage with at least 3 CPUs and 4 Gi of memory in Kubeflow. See Creating GPU-Enabled Notebook Servers. - In your notebook environment, activate the Ray-specific Python kernel.
-
To ensure optimal performance, use dedicated directories containing only the
essential files needed for that job submission as a working directory.
NOTE
If you do not see the
Ray-GPUfolder in the<username>directory, copy the folder from theshared/ezua-tutorials/current-release/Data-Science/Raydirectory into the<username>directory. Theshareddirectory is accessible to all users. Editing or running examples from theshareddirectory is not advised. The<username>directory is specific to you and cannot be accessed by other users.If theRay-GPUfolder is not available in theshared/ezua-tutorials/current-release/Data-Science/Raydirectory, perform:- Go to GitHub repository for tutorials.
- Clone the repository.
- Navigate to
ezua-tutorials/Data-Science/Ray. - Navigate back to the
<username>directory. - Copy the
Ray-GPUfolder from theezua-tutorials/Data-Science/Raydirectory into the<username>directory.
-
Open the
ray-gpu-executor.ipynbfile in the<username>/Ray-GPUdirectory. -
Select the first cell of the
ray-gpu-executor.ipynbnotebook and click Run the selected cells and advance (play icon). Continue until you run all cells.
Results