About HPE Ezmeral Data Fabric on Kubernetes
HPE Ezmeral Data Fabric on Kubernetes enables you to run HPE Ezmeral Data Fabric services on top of Kubernetes as a set of pods by:
- Creating Data Fabric clusters for storing data.
- Creating tenants for running Spark jobs inside pods.
This feature is not available in HPE Ezmeral Runtime Enterprise Essentials.
Creating a Data Fabric cluster and installing the tenant components runs HPE Ezmeral Data Fabric on Kubernetes as a fully native Kubernetes application. Deploying a Data Fabric cluster offers the following benefits:
- Independent and elastic storage and compute scaling.
- Simplified installation, upgrades, and scaling for easier "Day 0" and "Day 2" use.
- Pre-wired for data-intensive workloads, such as Spark and KubeFlow.
- Built for security, including user authentication and data encryption both at rest and in transit.
A tenant within a Kubernetes cluster is a workspace that contains compute runtime pods (such as Spark applications) that access and/or process data from the Data Fabric cluster, with no requirement for an internal Data Fabric cluster in the same Kubernetes environment. You can configure tenants to access data on external storage clusters that reside on bare-metal and other environments. Each tenant can connect to different storage clusters, but a single tenant cannot connect to multiple storage clusters.
The following installation scenarios are available:
- Scenario 1: Dedicated Data Fabric cluster. This scenario uses a dedicated Kubernetes cluster with the sole function of running HPE Ezmeral Data Fabric to provide data services. See Scenario 1, below.
- Scenario 2: Co-located Data Fabric cluster. This scenario co-locates with a Compute cluster. HPE Ezmeral Data Fabric runs alongside other workloads sharing a single Kubernetes cluster. See Scenario 2, below.
HPE Ezmeral Data Fabric on Kubernetes Configurations
You can configure HPE Ezmeral Data Fabric on Kubernetes with any of the following configurations:
- Requirements for HPE Ezmeral Data Fabric on Kubernetes — Recommended Configuration: Explained in this topic.
- Footprint-Optimized Configuration. See Requirements for HPE Ezmeral Data Fabric on Kubernetes — Footprint-Optimized Configurations
Namespaces Created for HPE Ezmeral Data Fabric
HPE Ezmeral Data Fabric uses namespaces to separate and isolate resources and applications. The following illustration shows the namespaces created as part of an installation by the bootstrap utility. This example shows the infrastructure namespaces that do not reflect any installed Data Fabric clusters or tenants.
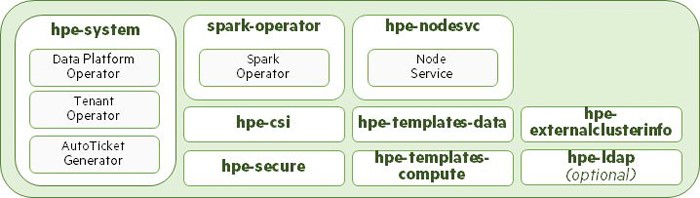
The bootstrap utility creates the following namespaces in each Kubernetes environment:
hpe-system- This namespace is created for Data Fabric and Tenant operators, and the Autoticket Generator pod, in order to reduce the surface area for security vulnerabilities. Operators running in this namespace have privileges that Operators running in other namespaces (such as the Spark operator) do not have.spark-operator- This namespace is created for the Spark operator.hpe-csi- This namespace is created for running the HPE Ezmeral Data Fabric Container Storage Interface (CSI) version 0.3 pods, described here. CSI is an industry-standard interface that enables containerization of volume plug-ins that are agnostic to the underlying node for volume plug-in driver binaries. The CSI driver also provides POSIX support for an ObjectStore pod to connect to the Data Fabric cluster, as described in MapR Container Storage Interface Storage Plugin Overview and CSI Examples. (These links open external websites in a new browser tab/window.)hpe-nodesvc- This namespace contains adaemonsetofnoderservicepods that are responsible for labeling and annotating nodes for use with HPE Ezmeral Data Fabric.hpe-templates-data- This namespace contains a set of default config maps and secrets used by the pods created by the Data Fabric operator. These config maps contain the configuration files used by storage cluster services contained in these pods. For example, thecldb-cmconfig map contains thecldb.conffile used by a CLDB pod to read configuration settings.hpe-templates-compute- This namespace contains a set of default config maps and secrets used by the pods created by the Tenant operator. The config maps contain the various configuration files used by tenant services contained in these pods.hpe-externalclusterinfo- This namespace contains the information about external, existing storage clusters including information about the locations of various cluster components like CLDB and Zookeeper nodes, as well as secrets used by external tenants to connect to storage clusters.hpe-ldap- This optional namespace contains anopenLDAPpod and service. During bootstrapping, if the authentication choice made is to use theEXAMPLE openLDAPservice, then this will be the namespace in which it is generated.
The following namespaces are also used:
-
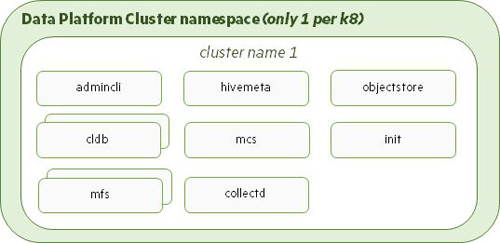
Data Fabric Cluster: The Data Fabric operator creates the Data Fabric Cluster namespace and specifies the name of this namespace in the Data Fabric Custom Resource. The Data Fabric cluster runs in this name space, and pods for every required cluster component are created in this namespace. The following illustration shows the namespace and pods generated when the Data Fabric operator detects a new Data Fabric Custom Resource (CR) file created in the Kubernetes environment:
-
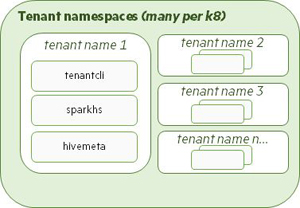
Tenant: The Tenant operator creates tenant namespaces to run compute applications (e.g. Spark). Other tenant services, such as Hive Metastore, a Tenant CLI, and Spark History Server can also run in these namespaces. Multiple tenant namespaces can exist within the Data Fabric Cluster namespace. These namespaces are created when the Tenant operator detects new Tenant Custom Resource (CRs) file created in the Kubernetes environment.
Data Fabric Operators and Custom Resources
Native Kubernetes only has the notion of pods and pod lifecycles. Complex multi-tiered applications such HPE Ezmeral Data Fabric require higher-level management. Kubernetes operators are a standard Kubernetes design pattern that simplify starting complex Kubernetes applications and also manage the entire application lifecycle, including complex upgrades. For more information, see Operators (link opens an external website in a new browser tab/window). An Operator consists of two components:
- Custom Resources (CRs): See Custom Resources, below.
- Controllers: A Controller builds what is specified in the applicable CR.
HPE Ezmeral Data Fabric includes the following Kubernetes operators:
- Data Fabric: Creates Data Fabric clusters.
- Tenant: Creates tenant namespaces for running Spark applications. The
tenant references either:
- The internal Data Fabric cluster residing in the same Kubernetes environment.
- A different storage cluster external to the Kubernetes cluster.
- Spark Operator: Starts Spark jobs inside existing tenants. A Spark job creates a Spark cluster on the fly. A Spark driver pod launches a set of Spark executors that execute the specified job.
Custom Resources
A Custom Resource (CR) Kubernetes component is a valid instance of a Custom Resource Definition (CRD) that adds new types to Kubernetes via a YAML file that contains settings for customized application installation in the Kubernetes environment, as described here (link opens an external website in a new browser tab/window). The following sample CRs are available:
You may either:
- Customize and deploy the included sample CRs for Data Fabric clusters and tenants.
- Create and deploy your own custom CRs.
Deploying Data Fabric Clusters and Tenants
There are two ways to deploy Data Fabric Clusters:
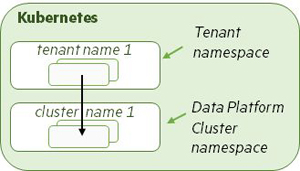
Scenario 1: Tenants Using Internal Data Fabric Clusters
You can deploy both a Data Fabric cluster and multiple Tenants in the same Kubernetes environment within HPE Ezmeral Runtime Enterprise. The following illustration depicts both a Data Fabric cluster and a tenant for running Spark applications created in the same Kubernetes environment. Pods are created for both the Data Fabric cluster and tenant components, and tenant containers access data in the internal Data Fabric cluster.
Scenario 2: Tenants Using External Storage Clusters
Having an available installation of an HPE Ezmeral Data Fabric storage cluster allows you to create a Kubernetes tenant that uses this external storage. You can also configure Spark applications from an HPE Ezmeral Runtime Enterprise tenant to connect and access the external storage cluster, such as HPE Ezmeral Data Fabric on bare metal. A Tenant namespace and various support files are created to hold this external connectivity information. The following illustration depicts applications in a tenant connecting to and accessing data in a storage cluster located either on premises or in another supported environment.
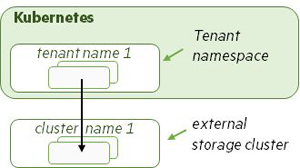
A Tenant can connect to only one storage cluster, but different Tenants can connect to different storage clusters. And multiple Tenants can connect to the same storage cluster.
Container Storage Interface
HPE Ezmeral Data Fabric incorporates an optional Container Storage Interface (CSI) Storage Plugin that exposes HPE Ezmeral Data Fabric to containerized workloads. If the CSI is installed, the bootstrap utility offers the option either to install or not to install CSI. CSI is installed by default, but HPE Ezmeral Data Fabric can operate without it. See Using the CSI and Container Storage Interface (CSI) Storage Plugin Overview (link opens an external website in a new browser tab/window).