GPU
Describes how to identify and debug issues for GPU.
GPU Not Working as Expected
Upload and run Check_gpu_card.ipynb notebook file in GPU-enabled notebook servers. See Creating GPU-Enabled Notebook Servers.
- To access the NVIDIA CLI in the
hpecp-gpu-operatornamespace, run:kubectl exec -it -n hpecp-gpu-operator daemonset/nvidia-device-plugin-daemonset -- bash -
To show the Python 3 process, run:
nvidia-smiIf the output does not show the Python 3 process, contact Hewlett Packard Enterprise support.
Ray
- Ray job hangs when you request more than available GPU resource in the Ray cluster.
-
When you request more than available GPU resource in the Ray cluster, the Ray job hangs.
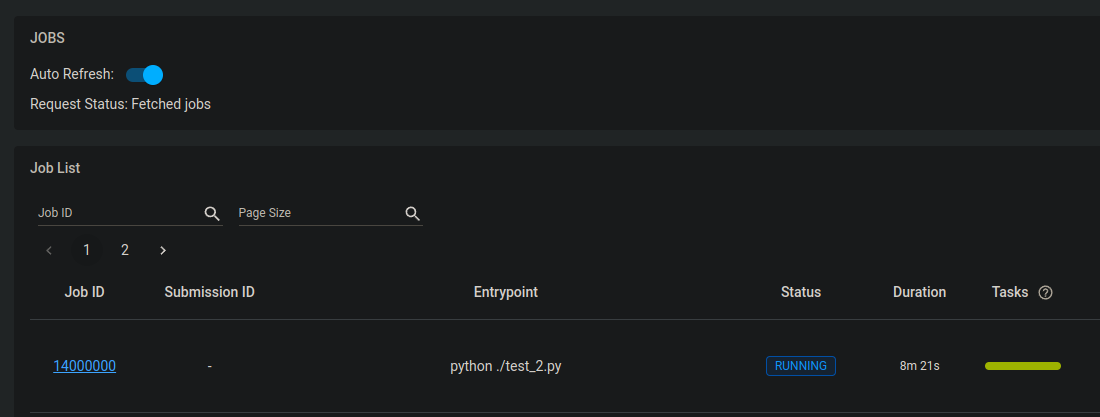 When you go to the logs in Ray Dashboard, you can see the following general log entry. However, this log entry does not specify that the job is hanging as more than available GPU resource is requested.
When you go to the logs in Ray Dashboard, you can see the following general log entry. However, this log entry does not specify that the job is hanging as more than available GPU resource is requested.[2023-07-20 08:18:09,674 I 25723 25723] core_worker.cc:651: Waiting for joining a core worker io thread. If it hangs here, there might be deadlock or a high load in the core worker io service.To confirm that the job hanging has more than the available GPU resource requested, you can perform the following checks:-
Run the following command to get the tasks summary:
kubectl -n kuberay exec kuberay-head-2dj8n -- ray summary tasksOutput: When you run thekubectlcommand to check the tasks summary, you can see the job is pending as follows:Defaulted container "ray-head" out of: ray-head, autoscaler, init (init) ======== Tasks Summary: 2023-07-20 08:15:25.292285 ======== Stats: ------------------------------------ total_actor_scheduled: 12 total_actor_tasks: 12 total_tasks: 192 Table (group by func_name): ------------------------------------ FUNC_OR_CLASS_NAME STATE_COUNTS TYPE 0 fibonacci_distributed FINISHED: 160 NORMAL_TASK PENDING_NODE_ASSIGNMENT: 32 1 RayFraudDetectionExperiment.run_experiment FAILED: 2 ACTOR_TASK FINISHED: 10 2 RayFraudDetectionExperiment.__init__ FAILED: 2 ACTOR_CREATION_TASK FINISHED: 10 -
Run the following command to check the job status:
kubectl -n kuberay exec kuberay-head-2dj8n -- ray statusOutput: When you run thekubectlcommand to check the job status, you can see that job hangs until it gets the required resources as follows:Defaulted container "ray-head" out of: ray-head, autoscaler, init (init) ======== Autoscaler status: 2023-07-20 08:16:04.958109 ======== Node status --------------------------------------------------------------- Healthy: 1 head-group 1 smallGroup 1 workerGroup Pending: no pending nodes) Recent failures: no failures) Resources --------------------------------------------------------------- Usage: 0.0/3.0 CPU 0.0/1.0 GPU 0B/14.90GiB memory 0B/4.36GiB object_store_memory Demands: {'GPU': 2.0}: 32+ pending tasks/actors
-
Notebooks
- Notebook server creation will be in the pending state when you assign more than one GPU resource.
-
When you assign more than one GPU resource for notebook servers, the notebook server creation will be in a pending state. If you hover over the spinner, you can see the following message:
Reissued from pod/test-nb-0: 0/8 nodes are available: 3 node(s) had untolerated taint {node-role.kubernetes.io/master: }, 8 Insufficient nvidia.com/gpu. preemption: 0/8 nodes are available: 3 Preemption is not helpful for scheduling, 5 No preemption victims found for incoming pod.
For example:
Kale
- The Running Pipeline step will be in the pending state when you assign more than one GPU resource for Kale.
-
To confirm that the Running Pipeline step is in the pending state as more than one GPU resource is assigned for Kale, follow these steps:
- Perform the steps to specify the GPU resource in the Kale extension. See Specifying GPU Resources in the Kale Extension.
- Run the notebook via Kale.
- Go to Running Pipeline and click
View. You can see that the pipeline state is in a pending
state.
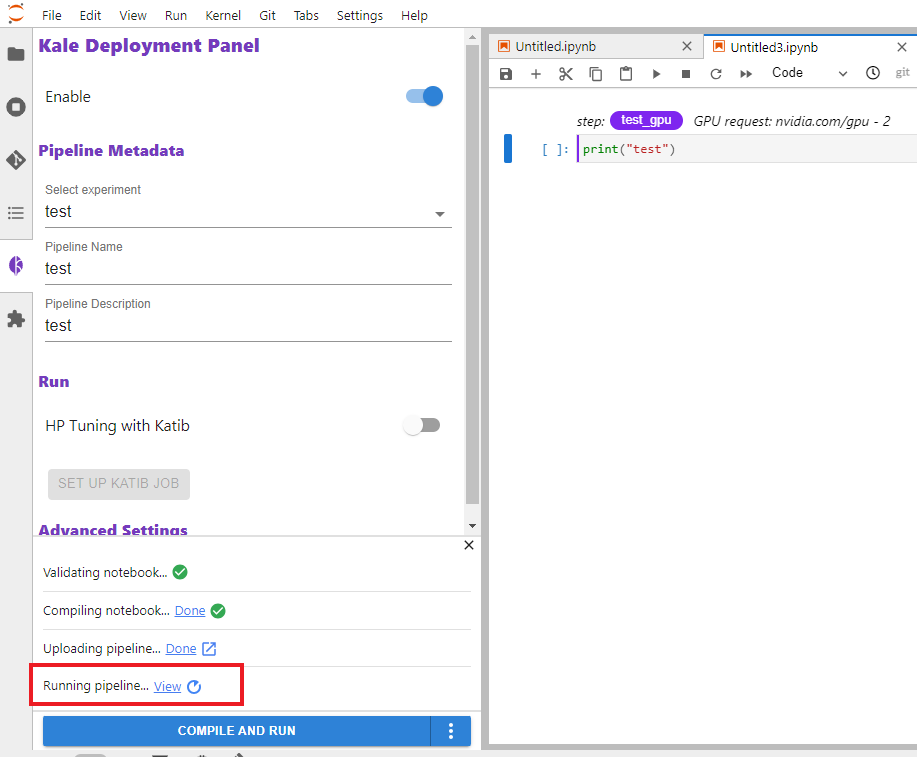
- Click on the step in the pending state. For example: Test gpu is the pending step.

Output: You can see the following message:
This step is in Pending state with this message: Unschedulable: 0/8 nodes are available: 3 node(s) had untolerated taint {node-role.kubernetes.io/master: }, 8 Insufficient nvidia.com/gpu. preemption: 0/8 nodes are available: 3 Preemption is not helpful for scheduling, 5 No preemption victims found for incoming pod.